storage
Ceph
- “Ceph is operated and not shipped”
Crucible
- Oxide’s storage service
- Composed of north and south
- https://rfd.shared.oxide.computer/rfd/0177
GFS (Google File System)
- Single control plane, master, scared it wouldn’t scale but it did
- Two specialized operations, record append and snapshot, with other basic file operations
- record append allows multiple clients to append from small records to a file
- snapshot allows the clients to create a copy of a file or a directory tree
- batch oriented workloads
- commodity servers
- Recovery?
- Checkpoints on metadata state, operation log
- shadow managers for recovery to serve read operations only, similar to how RW locks even have contention
- Notably, GFS places the consistency checking on the client library, where it requires the you (via the client library) to check
- Is not linearizable
Locks
- Read lock aquired on the directory (full path to the directory so that it’s not being edited or renamed)
- Write lock on the file name so that two or more processes cannot write at the same time
- Only a small region is locked, since not doing it carefully destroys performance
- If a manager dies after locking something, the lock goes with it since it’s a central master
- left to right locking, so locks are acquired in the shape of
/a,/a/b,/a/b/cfor read locks/a/b/c/file.txtfor write locks
Reading
- To read, user request is first processed by the GFS client that finds a chunk index
- Since each file is divded into 64MB chunks, the client just %’s by 64MB to find the appropriate idx
- Then the client requests this information from the manager to get the chunk index and chunk handle, which the manager tells an appropriate replica of
- Client then caches the metadata
Writing
- Two kinds of writes, a random write and an append (not POSIX compliant)
- Replicas hold leases that coordinate the writes
- Leases expire, and are only active for a small period of time. This means that if a bad replica has a lease, it will expire and a new node will be found
- Primary replicas exist because they allow the data to be consistent
Writing Workflow
- Random write and append operations are roughly the same, random writes use an offset for where the data is written, whereas the append just goes to the last chunk
- Note that the data is pushed to all the replicas
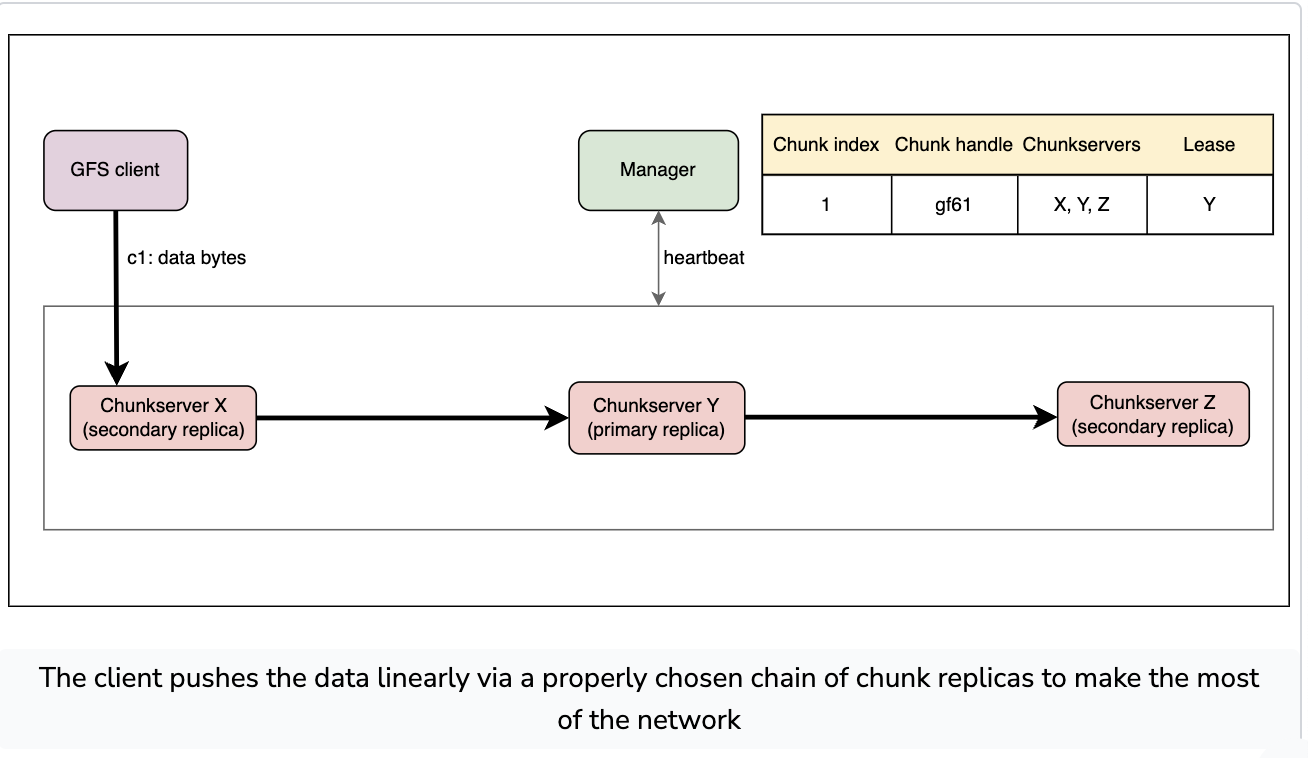
- The write (aka commit) happens to the main replica after all the replicas have recieved the data
- Replicas then ack whether they’ve received the data or not
-
Edge Cases on Writing
- If the last chunk has available space for appending data, then the chunk servers write that data
- If the chunk is already full, then the chunkserver asks the client to create a new chunk, which requires a new write and request loop from the manager
- If the last chunk is partially full, the chunkserver holding the last chunk will respond to the client with a message about the available server
-
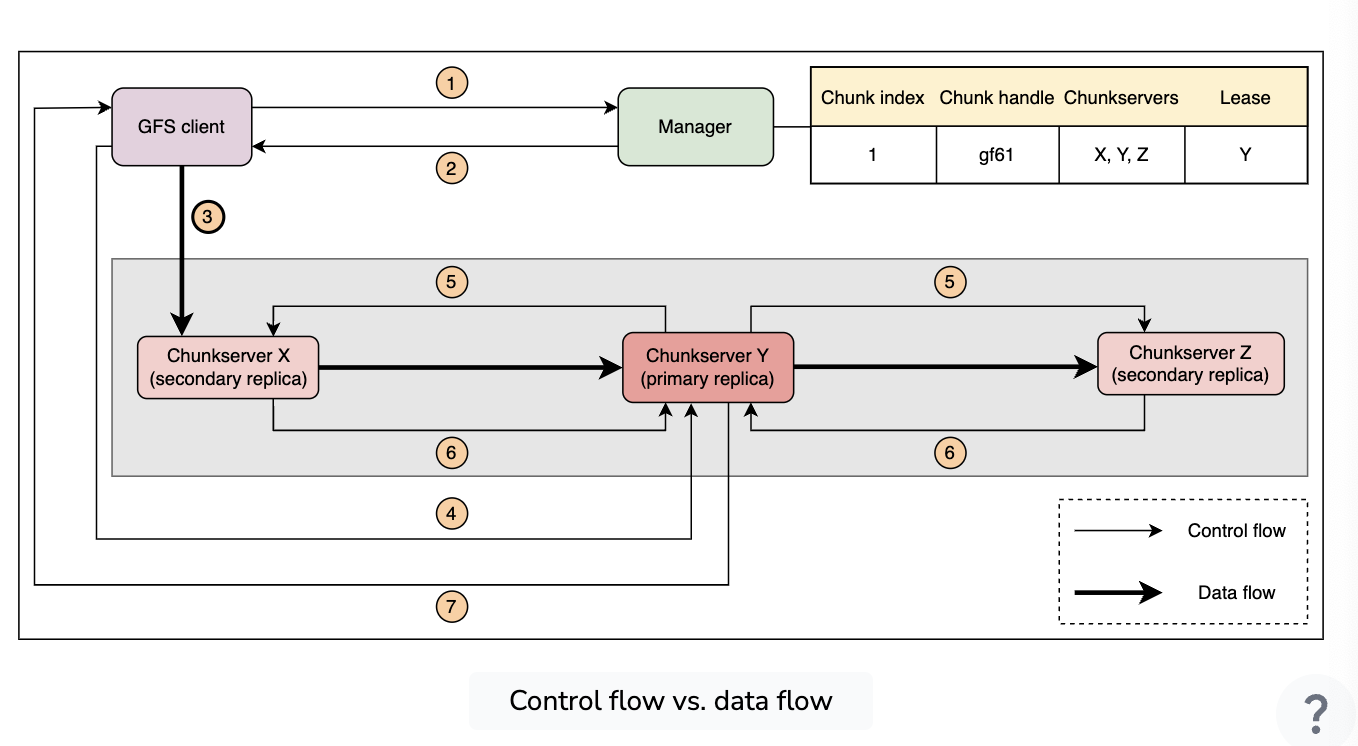
Control vs Data Flow
- GFS, critically, decouples the control and the data. The data physically flows via nearest-in-rack, but the manager still runs things
Deletes
- Garbage collection is done to avoid sync deletes
- Client says a delete needs to happen, so master creates a read lock on the dir and a write lock on the file
- Master then revokes the leases in progress, and waits for replicas to finish mutations
- Afterwards, delete actually happens
Consistency Model
GFS consistency starts from issues during write, we need to prevent writing over multiple times (mix data), and also issues with writing over the same data.
Possible States after mutations
- Consistent
- Inconsistent
- Defined - when mutations happen to a file and the applications can parse it and read it
- Undefined - when the region hasn’t properly changed data yet
How to actually maintain consistency?
- Random writes can result in serial success, where one lease or lock after the other allows writes to go through
- Concurrent success can happen when you have multiple writes on the same thing, resulting in mixed data
- Failure
- Serial success for appends happen the same as random writes, proper offsets are used
- Concurrent success is when two writes attempt to use the same offset
Dealing with Data Inconsistencies
- It doesn’t, you can have overlapping writes, the application level is responsible for locking
- For append however, appends happen as at least one atomic unit.
- GFS only deals with stale data because of bad replications
Metadata Consistency
- Chunkservers tell the metadata manager what offsets map to where, but the manager also keeps track of it
- We also use shadow managers when the client cannot reach the primary manager, which help facilitate primary reads
- also the shadow might be behind the primary, since it reads off of the master’s logs
- Master is also fully syncronous, it does not respond to the client’s requests for updating metadata until everything is done
- Failures can be retried by the client side, or present in the operation log
Scalability
- Scalability is achieved mostly through having multiple chunkservers, which can be easily added
- Availability is achieved by having three chunk servers per app by default
- Replication happens in the background if hosts are lost, and GFS manager has shadow managers that take over should the master go down
- Durability is acheived that there’s replicas for chunkservers and operation logs for the metadata
- Throughput is achieved by separating the data from the metadata flow
- Consistency is applied through relaxed consistency, most files are mutated by having append and reads
Colossus
- GFS single master could not hold everything
- Reed Solomon vs full replication
- parity bits are added for error correction, whereas full replication only uses
- Frontend has changed
- Curator -> horizontally scalable metadata servers
- Master metadata database
- Custodians -> horizontal scalers
- GFS was built on the assumption that file sizes were always going to outnumber metadata, but the biggest problem is that that may not be true, small blobs double their size with metadata
Client Library
- Still the most complex part, plays the same role as the GFS client
Control Plane and Metadata Database
- Metadata Database has moved to BigTable, but curators fill the role of serving metadata (horizonitally scalable metadata servers), and custodians manage the data (by moving files around), D file servers retain the same process as mapping over disks
Tectonic
- Facebook version of GFS, uses ZippyDB to handle async metadata management and block management
- Only allows one single writer at a time via locking
- Each block is 80MB
- Organizes the shards in zippy so that all the ones with the same sharding ID go on the same replica, which uses the
directory_id - Remote chunk store that actually stores the physical bytes
- Has a cache note called “sealing”, which restraints updates, allowing caches to be stored longer
- Has a 2pc for rebalancing when nodes need to go down for maintanence
- Divides traffic groups into 3, depending on priority
- Uses the Leaky Bucket Algorithm for traffic control
- Fat client library, client lib actually does RS encoding
Multitenancy
- Tectonic has quota limits for every user
- Also allows applications to mark itself in the traffic groups, similar to
nicevalues in linux - Tectonic distinguishes between emphermal and non-emphemeral resources for traffic sharding
- Emphemeral is IOPS and metadata query capacity, stuff that changes in real time
- Non-emphemeral is non-sharable resources that are once allocated to a tenant and will not be allocated to another, like storage
- TrafficGroups is an emphemeral sharing group, which is a collection of clients that have the same latency and IOPS requirements
- There’s 50 TrafficGroups per cluster, although this is configurable.
- Each tenant allocates the require emphermal resources based on TraffiCgroup and TrafficClasses (gold, silver, bronze)
- unused emphemeral resources are shared with the traffic group within the tenant of a high traffic class
- Client is actually responsible for this, the client library will check for spare capacity that is available within the same traffic group, then different traffic group of the same tenant, and finally spare capacity in the different tenants with the same TrafficClass priority
- Optimizations used by storage nodes
- Avoiding local hotspots is done with a weight round robin
- use a greedy optimiation for allowing low-latency requests to give up their turn for the high traffic class if the request can be completed after the completion of the high traffic class
- limits are set for all non-gold requests
- we have enough disks to rearrange the IO requests
- Authentication is done via a token based system
Tenant Specific Optimizations
- Data warehouse: write once, read many
- RS (reed-solomon encoding) encoded async writes
- RS encoding happens out of sync after the stuff is written
- Hedged quorum writes - generating reservation requests
- Improves tail latency
- Rather than sending the chunk to write further on the storage nodes, it sends only reservation requests, which then tell the nodes to accept the request of the reservation
- So if you have 5 nodes, you send out to 5, and just write to the 3 that respond first
- It’s like RS but for transactions
- RS (reed-solomon encoding) encoded async writes
- Blob storage (low latency, write many, read many, typically smaller than block size)
- Consistent append on partial blocks
- Whenever a small blob comes in, since they’re usually smaller than a block, we can just append to the block and perform replication on the partial block only
- To prevent partial block issues, there’s a lock on the writer
- Re-encoding blocks
- RS encoding on full blocks is IO efficient, but partial block is inefficient. Save the RS encoding until a full block has been written, and seal the block from further mutation, similar to SS tables
- Consistent append on partial blocks