linux
Tags: computers
- Currently Linux plumber and hobbiest occupy two different workds
- Desktop linux and DevOps middleware are paid employees, vs poeple who use suckless softawre, musl-based distros
Resources
Greybeard Qualification
Process
Internal datastructure struct task_struct {}:
- pid -> integer, will wrap around unused pids
- parent -> every proces has a parent, each one has a children
- tty -> in the old days, every process had an associated terminal called a tty
- uid -> user the process is running as
- gid -> group id
- A process can change its ids (
setuid) - From a sysadmin pov, what can you do to a process?
- create/send signals/ps or proc/strace
- each process has an address space, every process thinks it owns the entire theoretical memory of the computer
- why is kernel and user mapped into the same (virtual) address space?
- because it’s “cheaper” in mode switch, and “cheaper” context switch (kernel stays mapped)
- was actually attempted to be changed in https://lwn.net/Articles/39283/
memory
-
initialized and uninitalized data
-
break system call is used to increase heap size
-
heap sits on top and grows up and the stack grows down
-
in between space is used for shared libraries
-
32 bit 4GB
-
environment variables and cmdline is at the very top
-
kernel puts all of its data the top of the data structure
-
permissions on the memory regions like file
-
physical memory structure (https://www.youtube.com/watch?v=pI-HRRh7-dU)
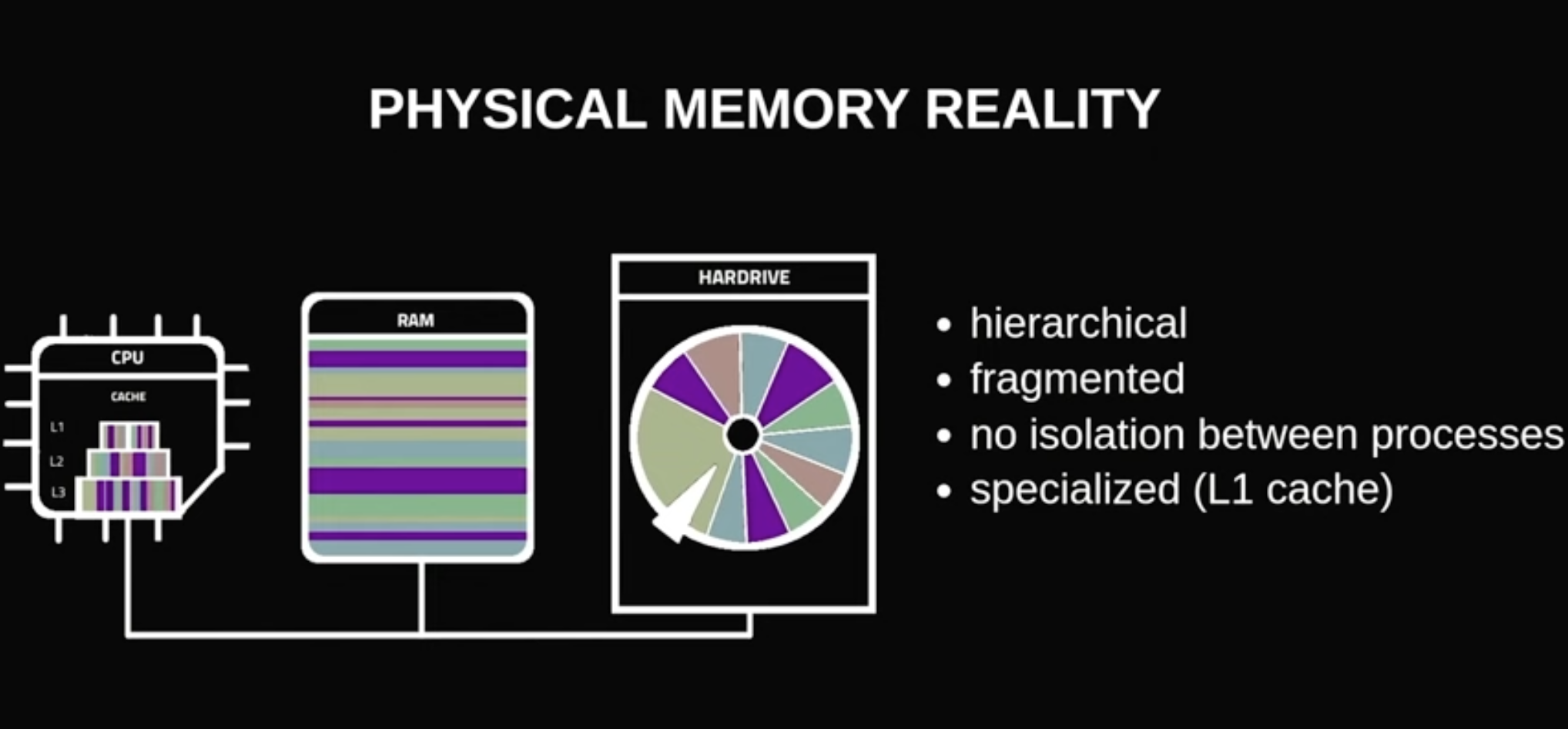
- icache vs dcache
- limits
- used to be important during timeshare systems
- rlimit or ulimit for stack size
- common one is the number of open files
- process priority
nicein shell- static priority
- dynamic priority
- real-time priority
- all related to scheduling
niceorgetpriority()orsetpriority()system calls
IPC
-
pipes
- internal buffer data structure
- two file descriptors, connected to each end of the pipe
- similar to a channel in go
- no temp file at all, all in memory
- one limitation: only exist between members of the same family within the same process three
- ls | wc works because both ls and wc are children of the chell
- FIFOs/named pipes, exist in the filesystem, acts like a regular pipe
- used for multiple processes
- cron uses a fifo in the kernel?
-
signals
- Killing a process can be done with
kill -s <SIGNAL> pid, sendSIGQUITto request a craceful quit orSIGABRTto request immediate termination- 32 original flavors
- 32 new flavors
- list with
kill -l - process can send signals to another process, or kernel sends it to your process
- common
- 9 - kill
- 15 - term
- 1 - HUP - hangup (for when you have a connection), now it’s used to reload config files
- 2 - INT - interrupt
- 19 - STOP - suspend in background
fgcommand to see
- 18 - CONT
- 14 - ALARM - timer in kernel, when the process is sent an alarm signal
- Killing a process can be done with
-
System V stuff
-
semget - semaphore
- SystemV semaphores can be manipulated as sets, and provides more control than POSIX ones
-
msget - message service get
-
shmget - shared memory
- most efficient is one setting data and another is reading
-
RPC - literally a remote procedure call, sent over to a different process usually on another process
-
mmap - a way to map a file into memory, then shared with another process, BSD trick
- you map a chunk of memory out to a file, and then its propagated, then you can have a set of memory that’s not tied to a particular file, then another process can share this file
- anon memory, not tied to a particular process, going to be paged out to swap space
- you map a chunk of memory out to a file, and then its propagated, then you can have a set of memory that’s not tied to a particular file, then another process can share this file
-
Execution, Scheduling, Processes, and Threads
- https://www.youtube.com/watch?v=hgb-1f6BlGI&list=PLSIUOFhnxEiC3YTdxwqZqgEY5imVL8U8J&index=3
fork()- fork creates a new process that’s an exact copy of the original
- copies memory, open files, basically everything
- not inherited: file locks and pending signals
- how does it work? why duplicate?
- fork as the parent returns >0, the pid returns child pid
- 0 is child
- <1 is error
file descriptor
- integer that represents a kernel data structure that has an inode, read position, etc
- pipes
- it’s possible to redirect the inputs and outputs of the program (another great idea of linux)
- now the child can something do different, including exec() a new program
execve()runs a new program, usually fork and exec is the pattern (although fork is bad now)- apache web server for example forks
- bash execs two programs and
- copy on write fork()
- since you’re just gonna exec, why bother copying the whole thing?
daemons?
- fork a child process, then the parent exits and leaves the child with parent as the init
- How do become a daemon?
- close all open files
- become the process group leader
- process group, by default, a processes of the login shells is in the group
- signals get passed to everyone in the process group, such as shells hanging up
- set the umask
- what are the permissions I want to be sure that are turned off by default?
- change the dir to a safe space
- change your working directory to somewhere safe, the daemon should be in a place that’s somewhere safe
scheduling
-
CFS
-
linux is multi-processing, but they have to share one CPU
- At any time, each of the CPU’s in a system can be
- Not associated with any process, serving and hardware interrupt (Hard IRQs)
- Timer ticks, network cards, keyboards
- Handlers here have to be fast, most of the time it is an ack
- Not associated with any process, serving a softirq or tasklet (Software interrupt context)
- Much of the real interrupt handling work is done here
- Tasklets are dynamically registrable versions of software soft interrupt contexts, which means you can have as many as you want, and any tasklet will only run on one CPU at any time
- Running in kernel space, associated with a process (user context)
- Running a process in user space
- Not associated with any process, serving and hardware interrupt (Hard IRQs)
- Bottom two can preempt each other, but above is a strict hierarchy, kernel process cannot preempt a softirq, a soft irq cannot preempt a hardware interrupt
- At any time, each of the CPU’s in a system can be
-
scheduling is how the kernel manages these running processes and “take turns”
- “context switching”, take all the registers values out, load the register values
- instruction pointer
- where is the stack? this kind of stuff
- who gets to run next?
- who’s ready to run?
- every process has a task state associated with it
- when simply running, CPU-bound, the kernel will preempt a process
- everything is in a run queue
- process is in the task_running state, has a certain time quantum to run, by default 100ms
- kernel checks the process time quantum at every tick, causes the kernel to check on the state, if the process hasn’t exited or slept, guarentees that a process doesn’t run forever
- realistically it’s 1 ms now
- preemptive multitasking
-
all TASK_RUNNING processes are part of the runqueue
- length of the runqueue is called the “load average”
- uptime shows load averaged command
-
last minute, 5 minutes, 15 minutes averages
00:43:10 up 122 days, 35 min, 3 users, load average: 0.10, 0.10, 0.09
-
- vmstat also does this with
rprocs -----------memory-------- -- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 0 0 0 65022788 1420664 60968808 0 0 0 9 0 0 3 0 97 0 0
-
high load average means you’re trying to do too much on the system probably
-
- states
- TASK_RUNNING
- TASK_INTERRUPTABLE
- TASK_UNINTERRUPTABLE
- TASK_STOPPED (control z)
- TASK_TRACED (strace)
- EXIT_ZOMBIE (the process has ended, but remains in the tree)
- zombies are only leftover datastructures in the kernel
- only reason to keep it around is so that the parent can retrieve its return value
- is not running CPU or mem
- usually a sign that the someone hasn’t cleaned up
- orphaned zombies become children of init, but the init will clean it up
- EXIT_DEAD
- process has excited, but pages still need to be cleaned up
- “context switching”, take all the registers values out, load the register values
-
-
EEVDF
- New scheduler
- Now uses a “lag”
Memory Management
Virtual Memory
- We’re not compressing images anymore
- But still multiprocessing, so we need to maintain individual process space
- Memory mapping is a little different for the 64 bit versions
- Memory mapping gets changed all the times
Paging
-
Page sizes traditionally 4kb, but really if you’re a big boy we’re all huge pages now
-
There’s a page table, and we represent the address space of the program and how it’s mapped into the actual ram
-
One of the bigger issues with paging is that storing the page table and all it’s constitutant information can get quite large. So we avoid mapping all the pages
- When a process generates a virtual address, the OS and the hardware have to make it a meaningful real address
- note that if we store page tables in memory, hitting RAM would be prohibitively slow, so we do a TLB
-
page table entries change logical memory spaces into physical spaces, how they ordered, how they used, varies widely
-
you don’t have to map all the pages, but if they’re not in ram, where are they?
-
kernel allocates the pages, and mapped when a program is loaded at execute time
-
shared libraries (shared among various processes, chances are .so pages are already in RAM, so they map to another process address space)
- although now static binaries might be good enough since we have tons of ram now
-
context switching doesn’t involve memory changes
- means switching to different address spaces and different page tables
- address spaces can sit all in memory with enough ram, just change the register values, no freeing memory
- pages are copied out to swap (AND HIT DISK)
- reason why it’s called “swap”, to swap processes between context switches
- now you just move the pages out as you need to
-
typically a disk partition or a file, and we can have multiple swap spaces
mkswap(8)andswapon(8)swapon -sin terms of unix blocks- unix blocks are 512 bytes, each block is half a K, although now there’s different
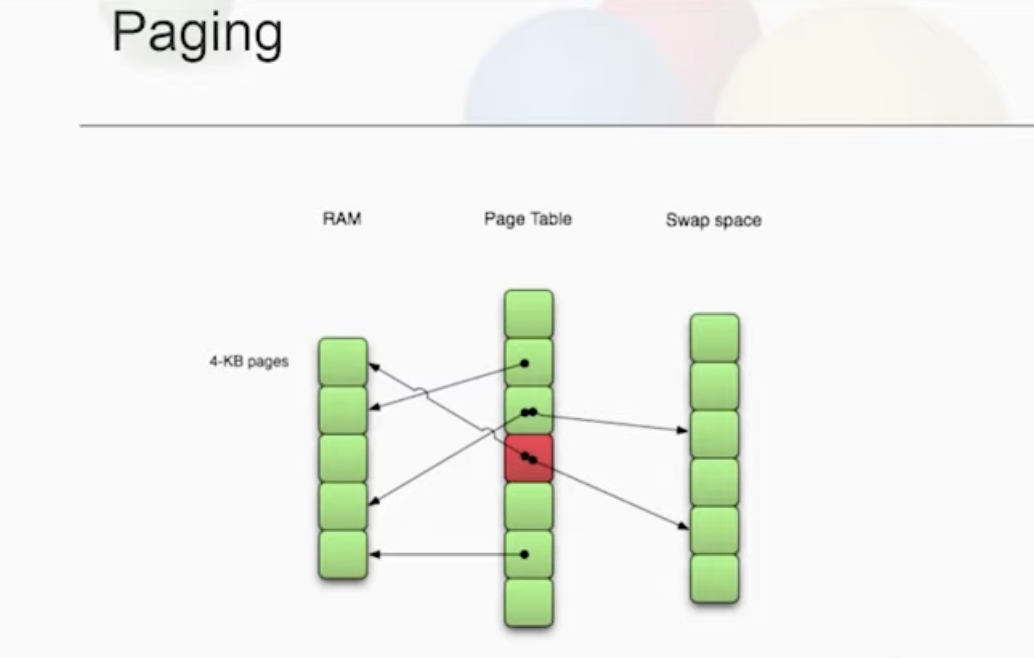
-
Possible to have memory on the swap space and in memory!
-
“dirty page” - means that one copy that has been created is not the same as a the one in swap anymore
- dirty pages need to reswap out
-
A “page fault” happens when you hit something that is not in RAM, which triggers a copy back from swap
-
happens on demand, which means paging in and out requires a very long wait
-
page ins are synchronous! the worst case
-
Linux KPTI:
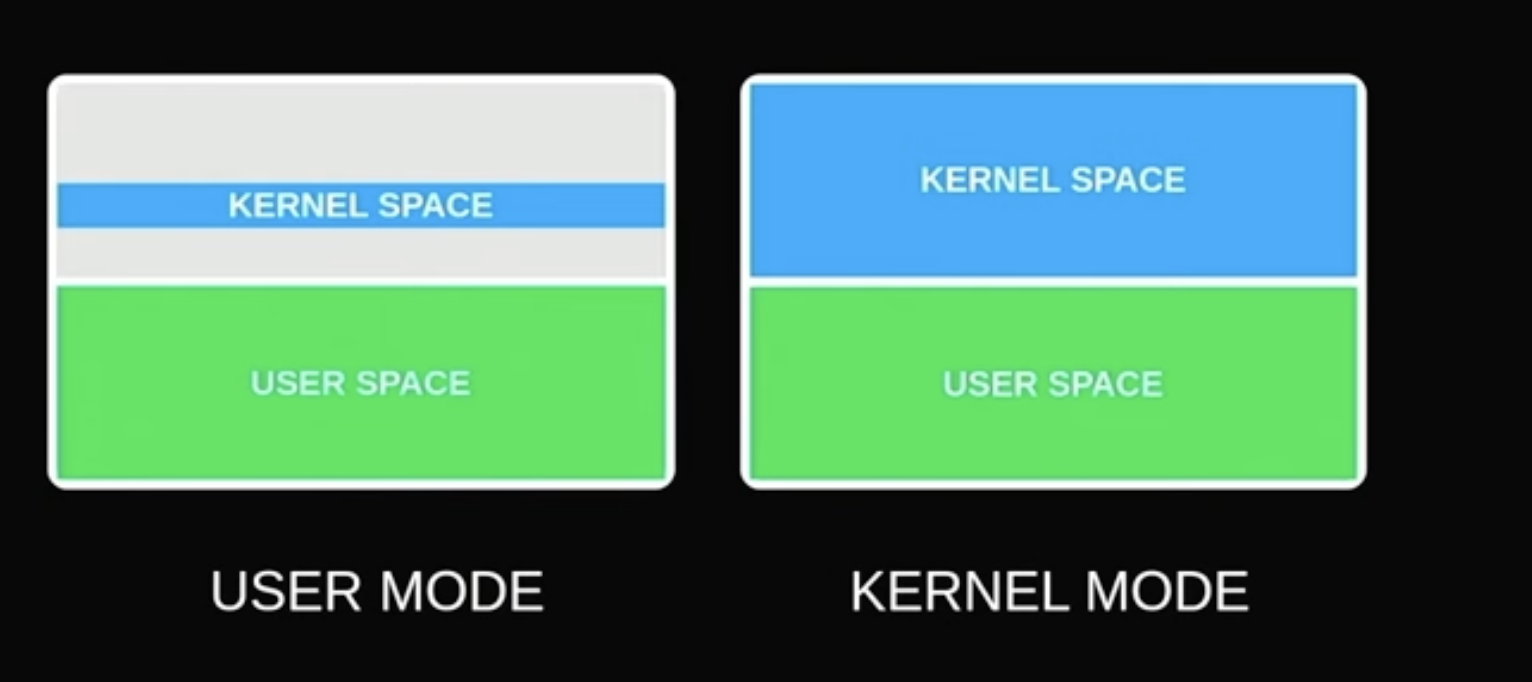
- separate page table, isolates user space and kernel space (against Meltdown), 5-30% performance degredation, causes partial TLB flushes
pmapgets you memory mappings
-
ASLR
- Where is it controlled?
/proc/sys/kernel/randomize_va_space
- Where is it controlled?
-
48 bit addressing
-
Linux uses the most significant bit for distinguishing between kernel space and user space (https://read.seas.harvard.edu/cs161/2018/doc/memory-layout/)

-
-
pgd, pud, pmd, etc
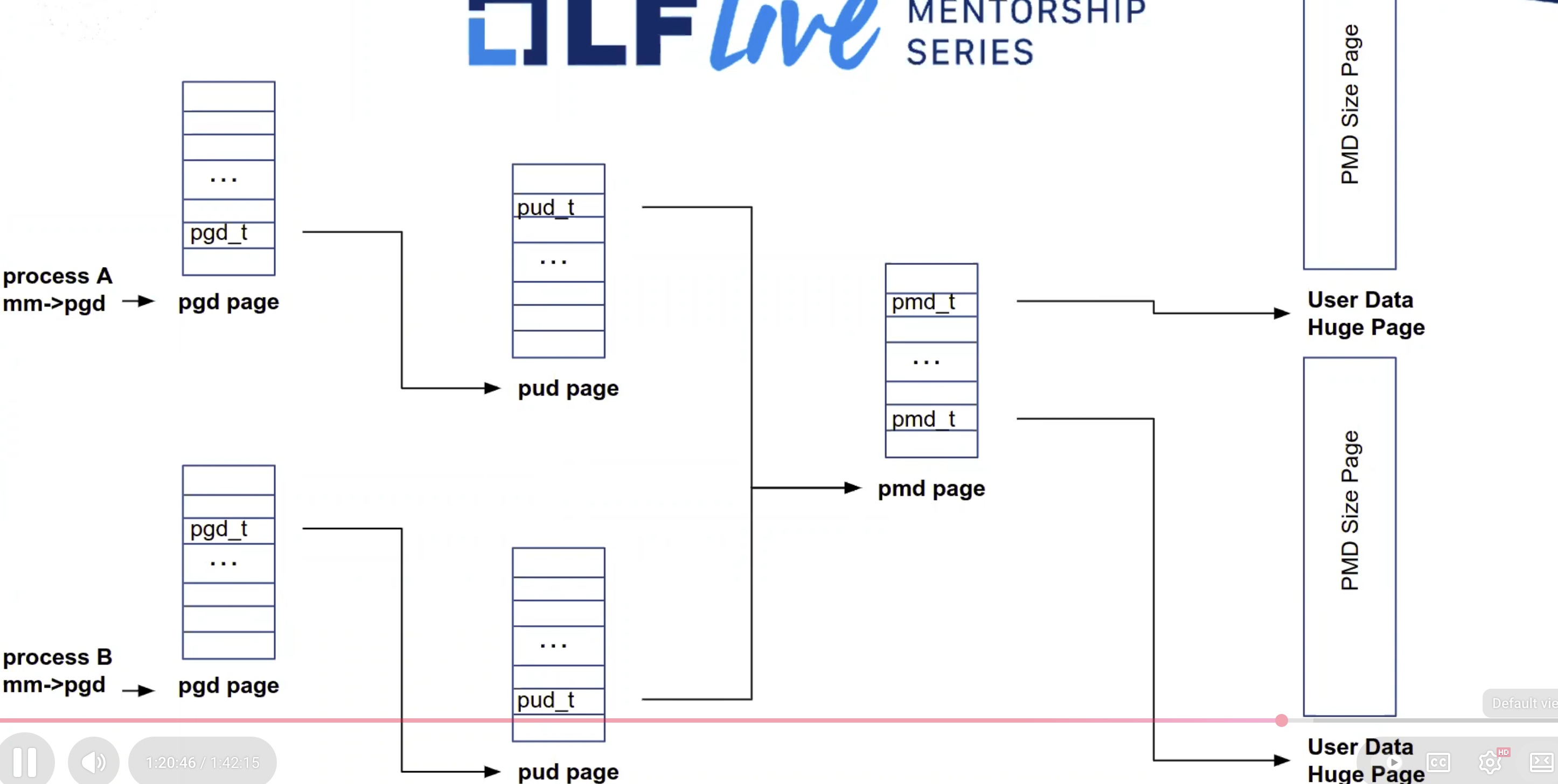
- Different layers of pgd
- Why do we even have multilevel paging?
- Because we want to reduce the amount of RAM. If we had a single level, the page table would have to be massive, it would have to allocate the whole table.
- Multilevel is a directory of pages
- https://lwn.net/Articles/717293/
-
Huge TLB (hugetlbfs)
- https://www.youtube.com/watch?v=n67gCNiKVcw
- hugetlbfs has been used in the past to reduce the cost of memory translation like any hugetlb, but there’s some issues
- But this pins memory, we can’t swap huge pages to disk, and no THP stalls.
- Transparent Huge Pages can try to act like huge pages, but the merging mechanism can cause CPU spikes and jitter. Same as compaction in LSM trees
- Get default huge page size in
/proc/meminfo - You can populate huge tlb on kernel boot, or at runtime
hugepage_cma-> contigious memory allocator- You can do it at boot time or at runtime, but doing at boot is a lot easier because of fragmentation
- You can mount a hugetlbfs filesystem, and all files in that filesystem are backed by huge pages
- You can’t swap or reclaim huge pages, so you just lose them, end up with a SIGBUS
- We can share the PMD entries in the table for hugetlbfs
- What kind of applications benefit from huge pages specifically?
- Databases engines
- Original users, they have a shared memory arena that each query process checks, so less memory lookups
- Java/JVM
- JVM allocates heap as one continuous block. This makes the GC scans faster by having to scan less on memory translation
-XX:+UseLargePages
- DPDK
- Bypass kernel stack, you need huge pages just for dealing with packet drops
- AI/ML Training
pin_memory=Truein pytorch speeds up memory usage because you need to shuttle around a lot of data
- Databases engines
- What about not huge pages?
- redis
- Uses
fork()aggressively - Relies on copy on write, but child procesess have to copy the entire page
- Uses
- webservers
- Not a lot of gain because requests are short lived and memory is already fragmented
- redis
- Arm Paging: https://wiki.osdev.org/ARM_Paging
File Mapping and Demand Paging
- old way: exec the process, create the VM space, copy the text, init data, then swap and copies as needed
- now /bin file is also copied into swap
- why not let the program on disk be its own swap space!
- file mapping - original copy of the program is a disk copy of what’s in memory, and then we reload them back from the file
- file mapping is swap
- then we can just map the file into memory, you don’t even need it in memory!
-
big win: only bring in pages as needed
-
mapping is instant, no waiting for the program to load
-
overall a win, demand-paging is good for most usecases (
lsfor example, you don’t load all the code for all the options)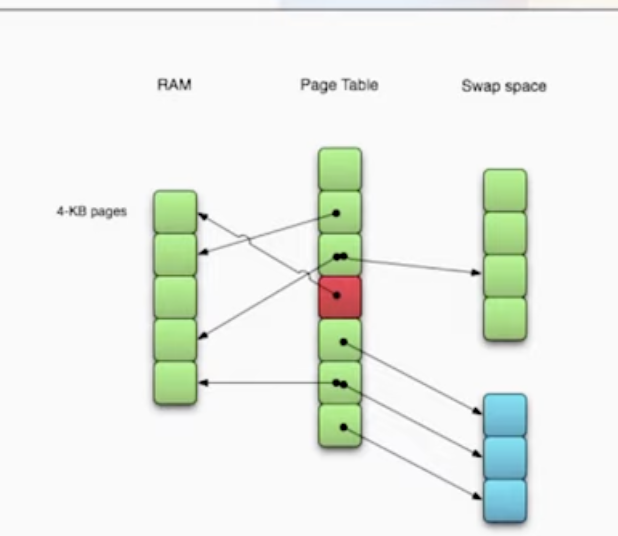
-
same thing happens for shared libraries -> libc is used
-
anon pages -> not represented by real world files, aka swap space is only needed for dynamically allocated files
-
shared libraries
ld.so -
copy on write
- when you fork a process, copy on write is a flag set on each page
-
demand paging, waiting for page faults
- normally: yes, but the alternative is on startup loading
- turn it off my setting
mlockormlockall, which assures stuff isn’t paged out
-
Monitoring VM
vmstat- first line is always an average (siso= page ins and page outs)- block IO is usually paging
swpd- memory in swap spacefree- RAM that’s free
File I/O
- Solaris also does this
- solaris has a page scanner that frees up scanner and each version also show scan rate
- if the page scanner was actually running and desperately scanning then we know what’s the memory problem
- All file I/O in linux is done via paging
- Paging isn’t necessarily bad
/proc/pid/maps/proc/meminfo/proc/pid/smaps- Shows you the size of the memory segment
- RSS -> how much of this segment is physically present in memory
- how much of it is shared
- how much of it isn’t shared
- how much of it is dirty
RAM and Swap
- How do you manage memory and free it up?
- When you’re running low on memory
- old times you do a clockhand algo, where you mark pages with one clockhand another was one that would free
- now there’s fancier algorithms, but we still want to get the least recently used ones
kswapd-> kernel thread that frees pages- now when things are dangerously low, now the OOMKiller comes in
- Uses an algorithm that tries to pick processes that can be killed
- if you’re too low on RAM and keep paging in and out, we’re “thrashing”
- happens on windows more
- in the old days
- swap >= ram
- since now you only need it for anon memory
- generally VM = RAM + swap
- You want activity in RAM, with enough ram, you should have zero swap
- Kernel still keeps page tables in memory if you have extra space
- I think this is the “cache”
- Everything that gets paged into memory and kept without looking at disk io
Startup and Init
Boot
- x86 -> 80x86 architecture
- raise the value of the RESET pin (on the processor)
- this goes through and intializes two important registers
- CS and EIP register
- CS - address of the stack and some other flags
- EIP - instruction pointer
BIOS
- This is coreboot/oreboot/libreboot
- Interrupt driven process that provides access to the hardware (DOS descended)
- Not a major part of the linux operating system, only used to get the kernel loaded
- Linux has its own device drivers and interrupt handlers
- POST (power on self test)
- ACPI (advanced config and power interfaces) - builds tables of devices with info
- initializes hardware - no IRQ or I/O port conflicts. Tabluates PCI (Peripheral Component interconnect) devices
- Looks for something to boot
- Devices
- Have an I/O port that the CPU can do IO to via port addresses
- When the device is ready to be talked to, it raises an interrupt and the linux kernel starts the driver
- ISA days
- part of the trick was picking the devices so that they didn’t conflict with the interrupts
- PCI helps with this by automating it so that they don’t conflict with each other
- You can choose what to do boot from now, and what order
- BIOS looks for the boot sector
- copy the first sector into RAM (512 bytes per sector), starting at 0x000 7c00
- then jumps to that address
Loaders LILO and GRUB
- First sector of a disk is the Master Boot Record (MBR)
- Containers a partition table and a program
- Within Linux, this is a boot loader. earlier linuxes had a bootloader (512 bytes)
- LILO (linux loader) and GRUB (Grand Unified Bootloader)
- GRUB is much more general purpose, has it’s own shell and can read file systems
- You can’t fit everything into 512 byte boot sector, so multistage
- First part is 0x0000 7c00, then it jumps to 0x0009 6a00, which then sets up the Real Mode stack
- Second part into 0x0009 6c00, which reads the OS list and lets the user choose the OS to boot
- If it’s linux, it displays loading, then loads the 512 bytes at the kernel 0x0009 0000, which then loads
setup()to 0x0009 0200, and then jumps to runsetup()
-
Real and Protected Modes
- Addressing modes in 80x86.
- Real mode: segement + offset, the segement address is shifted left by four bits (10 bits)
- Protected mode: uses page tables
- Now has a User/Supervisor flag
- When set to 0, page can only be accessed in kernel mode
- CPL (current privilage level) is 2 bits for the cs register
- CPL = 3 for User mode, CPL = 0 for Kernel mode (there’s 4 rings in intel, but we only use two)
Setup
- For ACPI systems, build a physical memory layout table in RAM
- Sets up the keyboard and video card
- Initializes the disk controllers
- If EDD (enhanced disk drive) services, uses the BIOS to build a table of hard disks in RAM
- Sets up the interrupt descriptor table (IDT)
- Different devices can raise interrupts and you want something to happen
- A table is a set of addresses that points to code that is run when an interrupt is run
- Resets the FPU
- Switches the CPU to protected mode
- Jumps to startup_32() (or startup_64 now)
- Initalizes segmentation registers and a provisional stack
- Zeros out the kernel’s uninitialized data
- Runs
decompress_kernel()- Kernel is decompressed and loaded into memory, and then jumps to 0x1000 0000
- second
startup_32()-
intializes segementation registers and a provisional stack
-
intializes kernel page tables
- Note that these cannot be swapped out unless we’re hibernating or something
-
stores Page Global Dir address in
cr3register and starts paging, setting the bit PG in thecr0register -
sets up the Kernel Mode stack for process 0
- what if there’s no task waiting for the kernel to schedule? the kernel schedules PID 0, which halts the CPU
- every millisecond, an interrupt happens, which then rechecks the run queues
-
- Nulls all the interrupt handlers
- Copies paramenters from the BIOS into the boot command into the first page frame (in RAM)
- Identifies the processor model
- Initializes the interrupt descriptor table to null handlers
- Jumps to
start_kernel()
Kernel Startup
- Nulls all the interrupt handlers
- Calls
sched_init()to initialize the schedulers - Initializes memory allocation
- Sets up interrupt handlers with
trap_init()andIRQ_init() - System date and time are set with
time_init - CPU clock speed determined by
calibrate_delay - Then we run
kernel_thread() - Finally we are at
/sbin/init!
Init and Run Levels
- Users run levels (0-6 typically)
- Distinguises between single user mode, GUI’s, etc
- Default values
- 0 - halt
- 1 - single user mode
- Booting into root halfway
- 6 - reboot
- S is used when entering runlevle 1
- Change with
telinit(8)- Unix applications know what name they’re called by, so egrep -> grep -E
- You can specify the run level at the command line (GRUB or LILO)
- File names
- In the unix world,
.tabis usually table, andrcis “run command” /etc/init.d/rc
- In the unix world,
inittabentries are what starts
RC Scripts
- Run command
- Takes a run level as an arg
- Then looks for a directory in
/etc/rc/\/.d - Runs each scripts with an action arg
- Run level 0, 6 action is stop
- Others are start
- To run a startup script, find the right run level, and look at the different scripts, and then set it there
- But these are init rc and not systemd
- Stopping processes - just run
pkill initcame out of SystemV, which was the original version- originally commercialized by AT&T
- Berkley did it with a different startup script
rc.boot,rc,rc.local
upstartin ubuntu
Block Devices and Filesystems
ioctl (Devices)
- Devices are special file
/devis devices- When we need to do IO on a device, just go out and access it!
- Block special files and character special files
ls -l->cfor character file,bfor block file- major and minor numbers, represents type of the device, and reprsents the instance
- 4k major numbers, 2^20 minor numbers
mknodis used to make a device special file- Nothing special about these files! You can make them anywhere
udevis a program that sits there and creates files in the/devdirectory- devices can register themselves or get a number assigned to them
- much effort has gone into making devices work together
- traditional device operations
open()close()read()write()seek()ioctl- lets you do particular things to particular device
- usually takes some integers (like everything in unix world)
- block devices
- tend to do I/O in terms of blocks
- like disk drives
- usually more random access
- disks for example
- character devices
- operate in bytes
- usually more seequential
- mouse/audio card/printer/tape/terminal for example
Block I/O
- How does block IO work?
- We want to write some bytes a disk, eventually we must turn this into a block
- Top level: Virtual file system
- Came along SystemV (release 4)
- Pre VFS, you had to mount a read/write for every single file system type
- VFS unifed all of this, generic read/write/open/close
- Cool thing that VFS brought: /proc file system! /cgroup file system! We can have file systems that don’t even represent a storage device
- Page cache
- There used to a buffer cache for blocks
- and page caches for pages
- now we only have one page cache
- when you make a write call to the disk, the kernel is actually taking the data to write it at a later time
- rapid return of writes is a performance gain but a reliability loss
- if you’ve written a lot of data, you might need to get it again! hence why it’s held in the page cache
- how pages stay around? We also page cache our writes
- NOT the pages that represent the memory map
- two different areas of memory
- page cache for regular files, page cache for block IO
- swapped data go into page cache, even special files
- shared memory trick? Memory map fake files in the page cache, and forks can read it back out
- Each page is owned by an inode
- also has an offset for that file
- We want to periodically scan the page cache for dirty pages and flush to disk
bdflushin the past
- We also want to track how long pages have been dirty and flush before too long in the cache
kupdatein the past
- Now kernel runs varying number of
pdflushthreads
- Mapping layer
- Most of the action
- FS takes the pointer to the data, allocates appropriate pages, and then turns it into blocks to be written
- FS knows how to talk SCSI or SATA or NVMe
- A disk is represented as a sequential list of blocks, which then we map over
- We also have a “segement”, we should try to find the blocks that are together, which can be sent together
- Pages are 4kb, sectors are 512 B, blocks can range between these two sizes (although pages are huge now)
- once blocks are known, send the request to the generic block layer via
submit_bh()andll_rw_block()for multiple blocks - arguments are direction (r/w) and buffer heads
- Generic block layer
- Gets sent data from the mapping layer
procs ———–memory———- —swap– —–io—- -system– ——cpu—– r b swpd free buff cache si so bi bo in cs us sy id wa st 0 0 0 65022788 1420664 60968808 0 0 0 9 0 0 3 0 97 0 0
- Generic block layer combines contingous blocks into segments called a
bio(block IO unit) - calls
generic_make_request()(send_bio_noacctnow maybe?) - Then it sends it to the device driver using the
strategy()routine
- file systems
- Stores data on disk
- Data and metadata
- Metadata is permissions, ownership, timestamp, size
- Efficient data access is important
- Usually metadata access is the most important
- Metadata is cached on the system
- Journaling helps (logging)
- Like the traditional DB two-phase commit
- First write log, then append to last
- Then you update the actual disk with the log
- If a disk is an inconsistent state, run
fsck-> but this is SLOW - Most journaling filesystems use it only for metadata, but some use it for all. This is usually configurable like
ext2andext3- Ext3 without journalism is just ex2
- You can put journals on a separate disk (since journal IO isn’t competing with disk as much)
Files
- inodes
- Every file system has an inode (contains all the information returned by
ls -l) - device
- mode
- links
- uid and gid
- size in bytes
- size in blocks
- Block addresses are stored too, 12 direct blocks, one indirect block address, one double-indrect block address, and one triple-indirect block address
- 15 total slots
- the reason there’s indirect is because the first 12k is stored in the file
- MB files therefore have to use extra blocks
- next address points to a block, that is filled with addresses
- second indirect block points to a block that is filled with addresses that go to a different block!
- third, so on
- direct: 12kb
- indirect: 256 blocks = 256kb
- double: 256^2 = 64MB
- triple: 256^3 = 16 TB
- this goes back at least to version 7
- atime, mtime, ctime
- atime -> access time, last time file was
open() - mtime -> last time file was modified
- ctime -> last time inode was changed (ctime is NOT creation time, most unix systems don’t track creation time)
- atime -> access time, last time file was
- Multiple directions that point to the same inode is a
hard link - One inode per file
- Every file system has an inode (contains all the information returned by
- Unix timestamps
- Since Jan 1st 1970 in UTC
- 32 bits
- Jan 18th, 2038
- Sparse files
- What if you write some bytes into the beginning, but then jump wayyy down and write later, where there’s no data in between.
- Logically, the bytes in between are filled with zeros
- Don’t allocate for stuff in between
- If you copy a sparse file, dumb copies will take a bad copy!
- Superblock
- Information about the filesystem
- Much of what is in the df command
Networking, Configuring & Building a Kernel
- OSI model -> physical, data link, network, transport, session, presentation, application - networks
- What a socket?
- IP address and port on each end, which uniquely identifies a connection
- Network layer implements IP to retransmit packets, but this is machine to machine
- Intermediate devices bridge this gap (usually a router)
- Ethernet/data link layer is what’s next, also packet switched with ethernet address 00:11:22:33:44:55 (mac address), NIC to NIC
- Networking - physical layer, signal level
- CSMA/CD (carrier sense multiple access with collision detect)
- old: 4 way stop sign, everyone tries to transmit and hope that there’s nothing there
- old: token rings, everyone gets a turn like a traffic light
- carrier modulates an IO signal
- twisted pair cables
- a network device is a special animal
- not a character or a block device
- no major/minor numbers
- hardware interface initiates IO
- not in
/dev - when a device driver gets registered, it adds the device to the internal list
- interface is also different!
openstophard_start_xmit()- start transmit packetsrebuild_header- using ARP (address resolution protocol)tx_timeoutnet_device_status- whennetstatgets calledset_config
- also
ioctl- SIOCSIFADDR
- SIOCSIFFLAGS
- “socket IO control set InterFace Flags”
- CSMA/CD (carrier sense multiple access with collision detect)
- Packet transmission
- Data is placed on a socket buffer
- call
hard_start_xmit - OS checks to make sure you’re doing less than the Maximum Transmission Unit (MTU)
- Places in transmission queue
- Driver processes queue and sends to hardware
- Packet Reception
- Two ways
- Interrupt driven (most drivers use this one)
- polled
- Recieves incoming data, places it in socket buffer
- If IO rate is too high, use polling
- Two ways
- Address Resolution Protocol
- Associates IP with a MAC address
- Broadcasts an ARP request on the network: “who has 10.1.2.3”?
- Saves entries into the ARP cache
- Manipulate with
arp
- Configure Interface
- always boils down to
ifconfig(8)
- always boils down to
- Linux Packet Filter
-
Basically the “firewall”, now managed by
iptablesorufwipchainsandipfwadm
-
Sets a list of rules, accept a match and execute an action
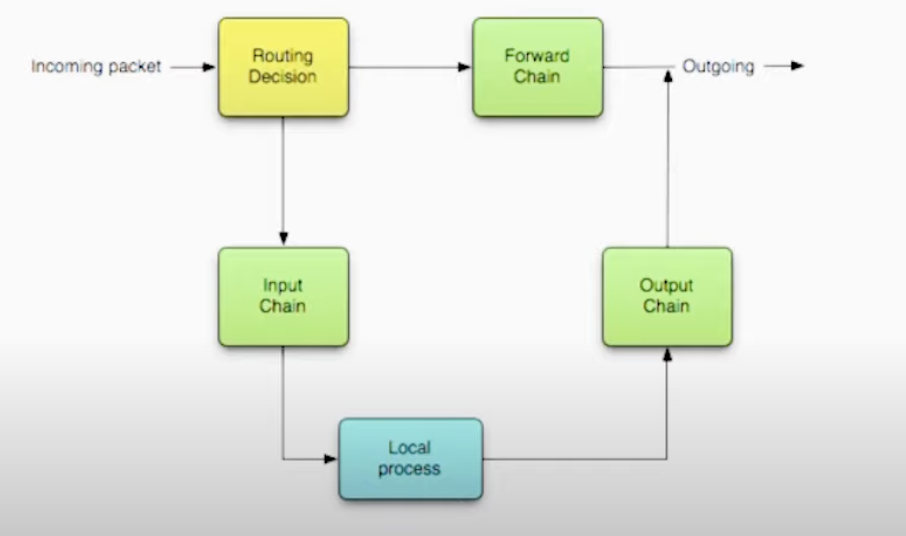
-
Three basic chains: input, forward, and output
- Each packet only follows one chain!
- there’s a default rule for every chain
-
Connection tracking?
ip_conntrack.omodule
-
List all the rules with
iptables -L -v
-
- Router table
- Kernel has a routing function?
- Usually one of the multiple interfaces, so router table
- Order matters, and search until we match a pattern
netstat -nralso shows you the router table (-n for hosts as IPs instead of having it do DNS)routecommand for checking the router table
- Kernel Build
- go to kernel.org
- need
bunzip2to decompress - can build as anyone, only need root to instal
- why?
- add a new feature/driver, or your driver was left out
- or to leave out specific drivers
Crashes
- Breakpad and Crashpad from google allow for dump tracing
- https://www.instapaper.com/read/1524786035
- Linux uses signals to register SIGABRT/BUS/etc
- By default, signal handlers are called on the same stack where the crash occured, which is fine for most cases except a stack overflow
- Apple computers use Mach exceptions: https://flylib.com/books/en/3.126.1.109/1/
- https://developer.apple.com/library/archive/documentation/Darwin/Conceptual/KernelProgramming/Mach/Mach.html
- https://docs.darlinghq.org/internals/macos-specifics/mach-ports.html
- Core dumps can be enavbled with
ulimit -c unlimitedon a temp basis. Otherwise configure/etc/security/limits.conf gcore -o filename PIDcan also be used to generate a core dump
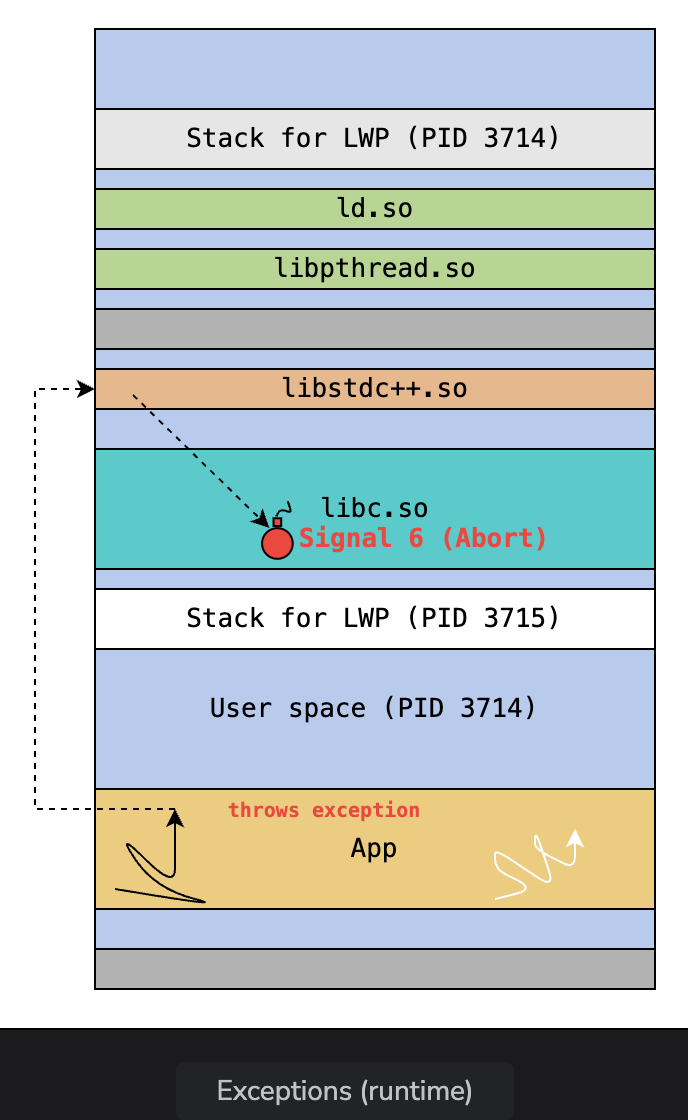
Exceptions
- Exceptions can happen because of invalid access or when a runtime check fails. This throws a
SIGABRT
Tracing
- https://jvns.ca/blog/2017/07/05/linux-tracing-systems/
- ebpf
- https://github.com/anakryiko/retsnoop?tab=readme-ov-file
- https://nakryiko.com/posts/retsnoop-intro/
Debian
perf performance issues
- https://bugs.debian.org/cgi-bin/bugreport.cgi?bug=911815
- when not linked against libbfd,
perfcalls out toaddr2linefor every address lookup, which is infeasible - possible solution: https://michcioperz.com/post/slow-perf-script/
- patches: https://lore.kernel.org/linux-perf-users/[email protected]/
- when not linked against libbfd,
Linux Audio
- Pipewire: http://pipewire.org
- provides low latency, graph based processing for audio
LD_PRELOAD and LD_LIBRARY_PATH
- Different usages on os x, uses
DYLD_LIBRARY_PATHandDYLD_FALLBACK_LIBRARY_PATH
Linux Kernel Headers
Cellular Modems
- https://forums.lenovo.com/t5/Ubuntu/P14s-Gen-3-Ubuntu-22-Fibocom-L860-GL-not-working/m-p/5177047?page=4#5967453
- https://forums.lenovo.com/t5/Fedora/Fedora-on-X1-Extreme-Gen-3-WWAN-Fibocom-L860-GL-4G-LTE-Advanced-Cat-16-not-working/m-p/5044699?page=7
- https://support.lenovo.com/us/en/solutions/pd031426
io_uring
Resources
- https://tigerbeetle.com/blog/2022-11-23-a-friendly-abstraction-over-iouring-and-kqueue/
- https://unixism.net/2020/04/io-uring-by-example-part-1-introduction/
- https://notes.eatonphil.com/2023-10-19-write-file-to-disk-with-io_uring.html
- https://kernel.dk/io_uring.pdf
- https://unixism.net/loti/what_is_io_uring.html
- https://kernel.dk/io_uring%20and%20networking%20in%202023.pdf
Related links
- https://github.com/axboe/liburing/blob/08468cc3830185c75f9e7edefd88aa01e5c2f8ab/src/include/liburing.h#L1445
- https://github.com/skypjack/uvw
- https://github.com/sfu-dis/mosaicdb/blob/master/dbcore/dlog.cpp
- https://martin-grigorov.medium.com/jvm-network-servers-backed-by-io-uring-244fea58bb19
- https://www.phoronix.com/news/JUring-IO_uring-Java
- https://www.datadoghq.com/blog/engineering/introducing-glommio/#did-you-just-come-up-with-all-of-that
- https://github.com/espoal/awesome-iouring
- https://media.ccc.de/v/38c3-iouring-ebpf-xdp-and-afxdp#t=810
Huge Pages
- https://www.evanjones.ca/hugepages-are-a-good-idea.html
- note that contiguity becomes a bigger problem with huge pages itself
Page Folios
- Got upstreamed in 2021
-
https://www.alibabacloud.com/blog/new-features-of-linux-memory-management---memory-folios_600565
-
Matthew Wilcox. “Memory Folios in The Linux Kernel.” June 23, 2022. https://www.infradead.org/~willy/linux/2022-06_LCNA_Folios.pdf.
-
A THP is a compound page, but internally we were still addressing the structs
- On startup, linux typically creates a massive static array called
vmemmapof struct page objects - you had a struct page for every 4kb of ram, each struct is 64 bytes
- So when you promoted 512 of these to a huge page, it had to mark the first one as the “head” and the rest as “tails” (
PG_TAIL) - But this was not really type safe, you had to check if
PG_TAILexisted, and always check for the head
void do_something(struct page *page) { // Is this a tail page? If so, find the head. struct page *head = compound_head(page); // Now operate on the head atomic_inc(&head->_refcount); } - On startup, linux typically creates a massive static array called
-
New:
struct folio { union { struct { /* public: */ unsigned long flags; struct list_head lru; struct address_space *mapping; pgoff_t index; void *private; atomic_t _mapcount; atomic_t _refcount; /* ... more fields ... */ }; struct page page; /* The overlay */ };We can cast between these as needed, so now
struct folio *folio = page_folio(page); // Internally calls compound_head() once. // After this, you use 'folio' and never pay the cost again. -
Type wise, folios guarentee you’re looking at the head
HVO/ HUGETLB_PAGE_OPTIMIZE_VMEMMAP
- When we promote to huge pages, we still have all these 64 byte page structs floating around
- HVO basically makes all the tails pointers to the head
Monitoring Tools
Guide: https://www.brendangregg.com/blog/2015-07-08/choosing-a-linux-tracer.html
- https://lttng.org/features/#insight
- https://www.kernel.org/doc/Documentation/trace/ftrace.txt
- https://sourceware.org/git/?p=systemtap.git;a=blob_plain;f=README;hb=HEAD
- https://netflixtechblog.com/introducing-vector-netflixs-on-host-performance-monitoring-tool-c0d3058c3f6f?gi=f30f393b4982
- https://www.brendangregg.com/perf.html
- https://lwn.net/Articles/608497/
- https://github.com/opendtrace/documentation
Sysadmin cookbook
> uptime; free -h; vmstat 1 5; iostat -xz 1 3 (base)
20:52:07 up 784 days, 22:44, 10 users, load average: 0.21, 0.29, 0.36
total used free shared buff/cache available
Mem: 125Gi 11Gi 14Gi 28Mi 100Gi 113Gi
Swap: 4.0Gi 34Mi 4.0Gi
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 35720 14710112 1773544 103664256 0 0 0 9 0 0 1 0 99 0 0
0 0 35720 14709860 1773544 103664272 0 0 0 6 6331 7469 0 1 99 0 0
0 0 35720 14709636 1773544 103664296 0 0 0 1230 7410 7821 0 0 99 0 0
0 0 35720 14709636 1773544 103664304 0 0 0 49 8180 8635 1 1 99 0 0
0 0 35720 14705540 1773544 103664304 0 0 0 921 7980 7958 0 0 99 0 0
Linux 5.14.0-284.25.1.el9_2.x86_64 (finland-rocky) 12/08/2025 _x86_64_ (12 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
0.65 0.00 0.22 0.03 0.00 99.09
Device r/s rkB/s rrqm/s %rrqm r_await rareq-sz w/s wkB/s wrqm/s %wrqm w_await wareq-sz d/s dkB/s drqm/s %drqm d_await dareq-sz f/s f_await aqu-sz %util
md0 0.00 0.01 0.00 0.00 1.74 4.03 0.00 0.06 0.00 0.00 34.80 65.77 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
md1 0.00 0.00 0.00 0.00 0.10 88.86 0.00 0.01 0.00 0.00 3.59 36.95 0.00 0.02 0.00 0.00 1.01 2486.87 0.00 0.00 0.00 0.00
md2 0.02 1.16 0.00 0.00 0.38 49.88 11.64 90.51 0.00 0.00 2.88 7.77 0.03 78.50 0.00 0.00 1.39 3020.88 0.00 0.00 0.03 0.76
nvme0n1 0.02 0.80 0.00 7.35 0.45 46.16 14.54 98.45 3.71 20.33 2.43 6.77 0.03 78.52 0.00 0.02 0.99 3021.41 6.61 2.54 0.05 3.15
nvme1n1 0.01 0.37 0.00 11.16 0.48 61.84 14.54 98.45 3.71 20.33 2.32 6.77 0.03 78.52 0.00 0.02 0.99 3021.41 6.61 2.38 0.05 3.15
avg-cpu: %user %nice %system %iowait %steal %idle
0.25 0.00 0.42 0.00 0.00 99.33
Device r/s rkB/s rrqm/s %rrqm r_await rareq-sz w/s wkB/s wrqm/s %wrqm w_await wareq-sz d/s dkB/s drqm/s %drqm d_await dareq-sz f/s f_await aqu-sz %util
md2 0.00 0.00 0.00 0.00 0.00 0.00 1.00 4.00 0.00 0.00 2.00 4.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.30
nvme0n1 0.00 0.00 0.00 0.00 0.00 0.00 8.00 15.50 0.00 0.00 4.62 1.94 0.00 0.00 0.00 0.00 0.00 0.00 7.00 3.43 0.06 3.80
nvme1n1 0.00 0.00 0.00 0.00 0.00 0.00 8.00 15.50 0.00 0.00 4.38 1.94 0.00 0.00 0.00 0.00 0.00 0.00 7.00 3.14 0.06 3.80
avg-cpu: %user %nice %system %iowait %steal %idle
0.42 0.00 0.42 0.17 0.00 99.00
Device r/s rkB/s rrqm/s %rrqm r_await rareq-sz w/s wkB/s wrqm/s %wrqm w_await wareq-sz d/s dkB/s drqm/s %drqm d_await dareq-sz f/s f_await aqu-sz %util
md2 0.00 0.00 0.00 0.00 0.00 0.00 6.00 40.00 0.00 0.00 3.17 6.67 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.02 2.20
nvme0n1 0.00 0.00 0.00 0.00 0.00 0.00 13.00 45.50 0.00 0.00 2.46 3.50 0.00 0.00 0.00 0.00 0.00 0.00 7.00 1.57 0.04 3.60
nvme1n1 0.00 0.00 0.00 0.00 0.00 0.00 13.00 45.50 0.00 0.00 2.46 3.50 0.00 0.00 0.00 0.00 0.00 0.00 7.00 1.57 0.04 3.60
- load average
- Ranges are 0 - infinite. A 1 value is a core. So if you have 12 cores, then 13 means that we’re all waiting on disk
- Get CPU count with
nprocorlscpu - Represents last 1, 5, 15min
- free -h
- Buff/cached is actually how much RAM you have that linux is using to cache disk blocks
vmstat 1 5- delay of 1 second, run 5 times- r (runnable) - how many processes are waiting for CPU
- b (blocked) - how many processes are waiting on IO
- swpd - virtual memory used, amount from the swap partition to disk. Changing numbers bad
- free - idle memory
- buff - raw block devices
- cache - amount used for page cache. Linux automatically brings in page caches
- si / so (swap in swap out) - kilobytes per second
- io (block in block out) - 1 block ~= 1kb, but kernel configs
- in (interrupts) - interrupts per second, really high numbers -> packet issue?
- cs (context switches) - massive means lots of locks and tlb shootdowns
- us (user space)
- sy (system)
- id (idle)
- wa (wait) - 0 /1, whether the CPU is waiting on disk
- id (idle)
- st (steal)
Perf
:ID: EE411A30-BFEB-4B3C-BD46-0281212E6744
Netlink
- https://docs.kernel.org/userspace-api/netlink/intro.html
- Evolved procotol that talks over sockets instead of fixed format C structures
Mounting
cgroups and names
- Foundations of containers for kubernetes (k8s)
Memory
Objects
objdumpto look at elf files
readelf
- Allows you to read a binary and check which parts mapped to where
readelf -l userProgram
Malloc Behaviors
- Malloc can use a data segement on the heap
- Or use an anonmyous mmap()
- Cares about the MMAP_THRESHOLD parameter
- Actually very similar to the erlang binary heap vs heap memory
- Heaps are not really a single region of memory
Syscalls (vsyscalls)
- vsyscalls maps a fixed memory region into user space
- some non-dangerous functions, l=such as
gettimeofday()are mapped into the user space - turns out bad with ASLR, and then fixed sizes, so deprecated in favor of vDSO
- some non-dangerous functions, l=such as
- vDSO
- kernel maps a small shared library into user space
- supports ASLR
- more syscalls space
- vvar
- read only variables for VDSO, specific heap for it
Stack
- how big is the stack? ulimit settings
- on x86, the stack always grows downwards
- since the stack is always a hardware and software feature
- the CPU is aware of the stack
- some arches have the stack grow upwards
envpstrings sit behind theargvstringsint main(int argc, charg *argv[],char *envp[]) {- auxillery vector sits behind theenvp