kafka
Tags: Computers
Kafka Debugging
- CP kafka has tools installed under
/usr/local/bin - Example:
/usr/bin/kafka-run-class kafka.tools.MirrorMaker --consumer.config source.config \ --producer.config dest.config \ --whitelist '.*' - Can check consumer status with
/usr/bin/kafka-consumer-groups --bootstrap-server <server:9092 --describe --group notification # or /usr/bin/kafka-consumer-groups --bootstrap-server <server>:9092 --list
SmallRye (java)
- Framework that abstracts over multiple queues, allowing you to send to multiple kafkas
Design
Producers
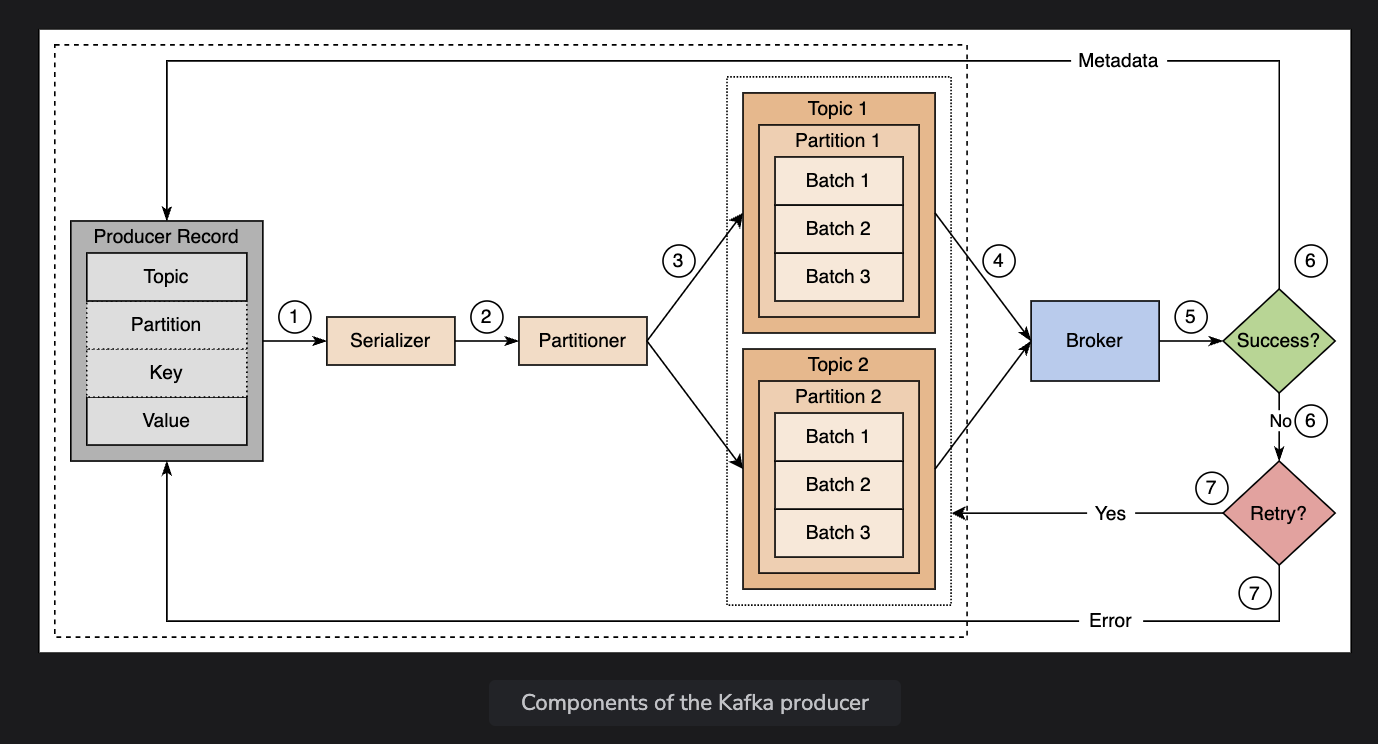
- Producer makes new messages
- Components
- Producer record: a record is kept for each message created, made of
<topic>, <key/partition>, <value> - Serializer: first thing a producer does to a message is to serialize the data into byte arrays
- Partitioner: after serialization, it returns the parittions of a specific topic where the message should be assigned to. If there’s a key, it uses a hash function on the message key (CRC32)
- If it’s a partition, it just assigns it to that partition
- Producer record: a record is kept for each message created, made of
- Default is one partition for each topic.
- Producers already know which topic and partition the message should be written to, and sends it to the appropriate broker
Broker
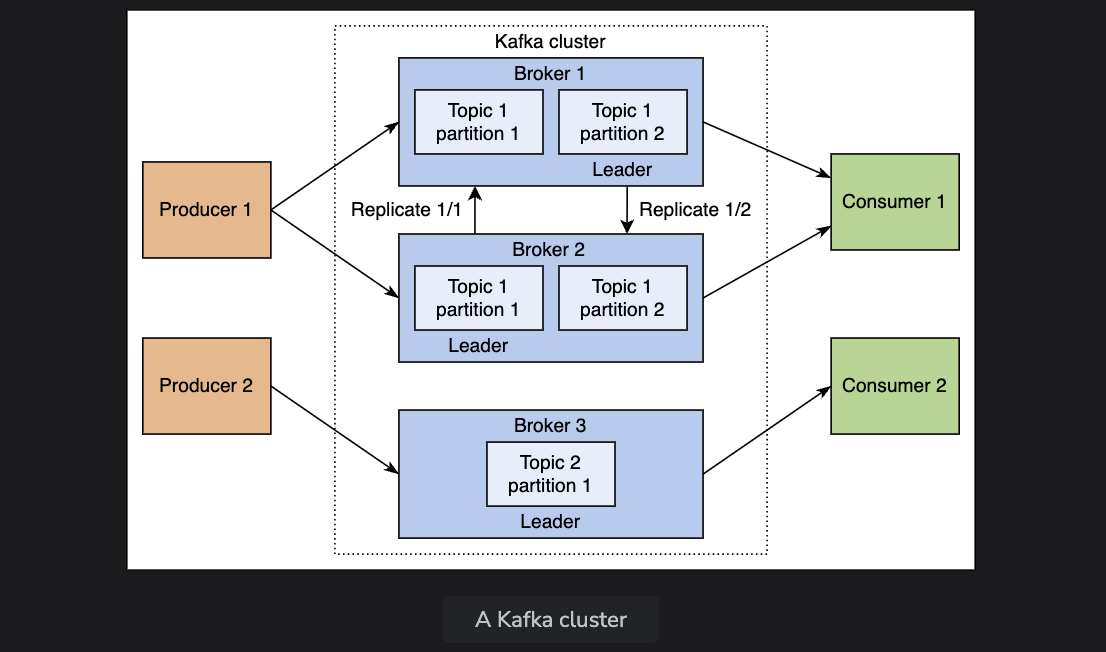
- Workers in kafka, which assign offsets to each message and stores them on disk
- There’s a cluster controller, elected via Paxos from Zookeeper, now raft, which is responsbile for assigning partitions to brokers, elects partition leaders, and monitors broker failures
- Since there’s multiple brokers, it allows you to scale horizontally.
- Tunable replication across different brokers
Consumers
- Consumers organize themselves into consumer groups, which are keep the offset of the last ACKed message
Efficiency
storage layout is simple
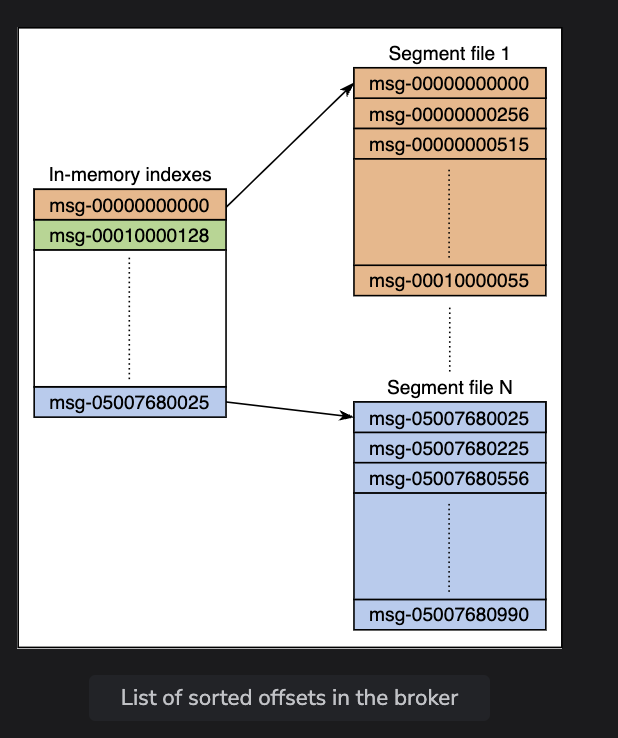
- a partition is “just” one big file, really a logical log that comprises a set of segement files approximately the same size.
- new messages are appended to the end of the file, and there’s some metadata that tracks the offsets each table has (similar to a sstable)
- Similar to blocks on datastores, you can just delete old chunks of logs as they expire
- every message has its id, but internally kafka addresses each message by it’s logical offset
- when aconsumer sends a pull request to a broker, the broker keeps a data buffer ready for consumption. The broker then proceeds to read off of the different segements
Efficient transfer
-
Data flows in batches, producers can dispatch multiple requests and consumers can ack batches back
-
Aggressively caches the data in RAM via the filesystem
-
for subscriptions, kafka uses a
sendfilesyscall that bypasses the application/kernel buffers by copying directly from one fd to another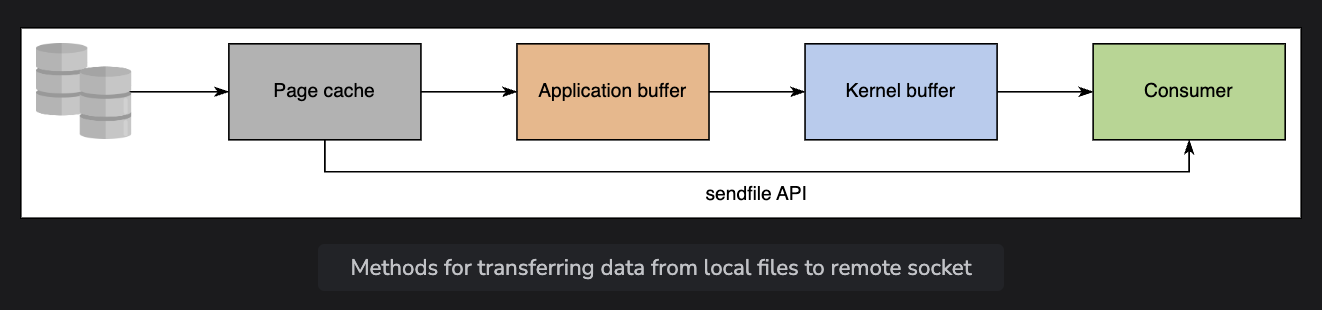
Stateless broker
- Consumption done by the consumer state is held in ZK, which helps in case of consumer failures.
- Kafka’s usage of time based SLA’s (rentention time) is what allows the brokers to delete messages even when the consumer hasn’t acked it
- Consumers can also rewind, as it allows you to go back on offsets if there’s errors
Distributed coordination
- Partitions are the smallest unit of parallelism, and those need to be consumed by a single consumer
- No specific manager nodes
- Zookeeper is responsible for keeping track of
- addition or removal of consumers and brokers
- registers consumers and brokers by creating emphemeral nodes
- all the brokers try to create an emphemeral node called a controller, but only one succeeds. The first one is the leader
- Rebalances processes in case brokers or consumers are added or removed
- Maintain the consumption from brokers and track the offset of the last consumed messages of a partition
- ZK registries
- Consumer registry - saves information in the consumer registry whenever it starts, has consumer group and subscribed topics
- Broker registry - saves information in the broker registry, has the hostname, port, and set of partitions
- Ownership registry - which consumer id is consuming from a specific partition
- Offset registry - stores info related to each subscribed partition
- Rebalancing has to occur when a consumer or producer dies, but this means that message delivery has to stop
- During rebalancing, different consumers have to take ownership of different partitions that are being read from. This means that they create ZK nodes to track them
Delivery guarnetees
- At-least-once delivery
- default, delivers each message once to each consumer group.
- Post rebalancing, just continue reading from the last offset
- Exactly once
- We can use unique keys in the messages and write the results to a system that supports keys
- Records and offsets can be saved somewhere else to dedup on the client end
- In-order delivery
- Kafka guarnetees that messages in a partition are delivered in a specific order
- No guarentees across multiple partitions
- Fault tolerance
- Avoids log corruption with CRC checks on the created logs
- Also replicates the partitions between different nodes
- Replicas that do not lag are called in-sync replicas
- considered to be replicas that have sent a heartbeat to ZK in the last 6 seconds (user configurable)
- replicas that fetched messages from the leader in the last 10 seconds (user confiugurable)
- Replicas that do not lag are called in-sync replicas
Design Wisdom
- Uses unconventional design, such as brokers not keeping state and not guarenteeing cross-partition ordering, but this pushes users to think more about parellism
- Key thing is that brokers do not keep state, state is kept in ZK