Databases
Tags: Computers
papers
Class
- https://15721.courses.cs.cmu.edu/spring2019/schedule.html
- https://www.youtube.com/playlist?app=desktop&list=PLSE8ODhjZXjbohkNBWQs_otTrBTrjyohi&themeRefresh=1
MariaDB
Calcite
- https://calcite.apache.org
- used in bodo.ai
Query optimizers
- how good are query optimizers? https://www.vldb.org/pvldb/vol9/p204-leis.pdf
Query Pushdown
- basically compliling the code and pushing the query down to the execution node
- https://blog.yugabyte.com/5-query-pushdowns-for-distributed-sql-and-how-they-differ-from-a-traditional-rdbms/
Foundation DB
- https://apple.github.io/foundationdb/data-modeling.html
- https://apple.github.io/foundationdb/developer-guide.html
DynamoDB
-
Similar to Cassandra, has partition key and sort key
-
Can horizontally partition across different nodes, similar to cassandra
-
Similarly, need to split a partition when it gets hot
-
There’s an automated systems that defines a read capacity unit and a write capacity unit. If it exceeds, it splits
-
Note that since almost always you have hot partitions
-
Each node has multiple partitions
- Each partition has two buckets, an allocation bucket or a burst bucket
- To handle a read, pick from any bucket
- To handle a write, the node needs to check the token availability of buckets in the nodes of the entire replication group
-
There’s a global admission control system, where each request router calls to a global token bucket
-
No fixed schema
- composite key created from the partition key and the sort key
hash(partition key), sort key - has secondary indexes like Cassandra
- composite key created from the partition key and the sort key
-
Similar to Cassandra
-
Automated adaption to traffic patterns, can move partitions around as needed
-
Uses multi-paxos for consensus
- Leader election from multi-paxos
- Write comes in to a laeder,
- Leader prepares to send acceptors containing the WAL to acceptors
- Acceptors acknolwledge the leader’s WAL and returns
- Leader will continue to renew lease as long as it is healthy
Partitioning
- Hot partitions are possible
- Alternatively, when a partition gets too big and needs to be pslit is throughput dilation.
- Bursting a partition means using the unused capacity on co-resident partitions
- Basically dynamo is organized into partitions, which contain collections of sstables. The hash value matches to a partition grouping, which are dynamic. Multiple partitions can be on the same machine, and bursts can be humored with
- Meaning there’s a problem of workload isolation on the co-resident partitions, we must find a way to maintain bursts (aka load balancing)
- Token buckets!
- When a node recieves a request, it checks for the available tokens in the allocation bucket.
- If there’s no space available, it checks the burst bucket
- This allows it to smooth out traffic
- Scaling this out, we can create a global admission control
- Central master
- Tracks the consumption of a table using tokens
- Request routers maintain local token buckets
- Request routers communicate to the GAC for new tokens
- All GAC servers are tracked by the GAC on an independent hash rings
- Request routers manage tokens and keep deducting tokens as they accept requests
- GAC estimates global token consumption using the information
- GAC allocates tokens that are available
- Basically this is the equivilant of having a QPS measurer
Replication
- WAL’s are used, but actually data replication is pretty slow
- Solved with log replicas, just replicate the logs themselves (metadata operations) rather than the whole memtable
- Silent data errors
- Hardware failures can also cause incorrect data writes, so it uses checksums underneath (presumably they have their own filesystem)
Availability
-
Similar to BigTable, replication groups are across different sets, and when a replication group is not healthy, the master replaces it
-
Master is done by leader election
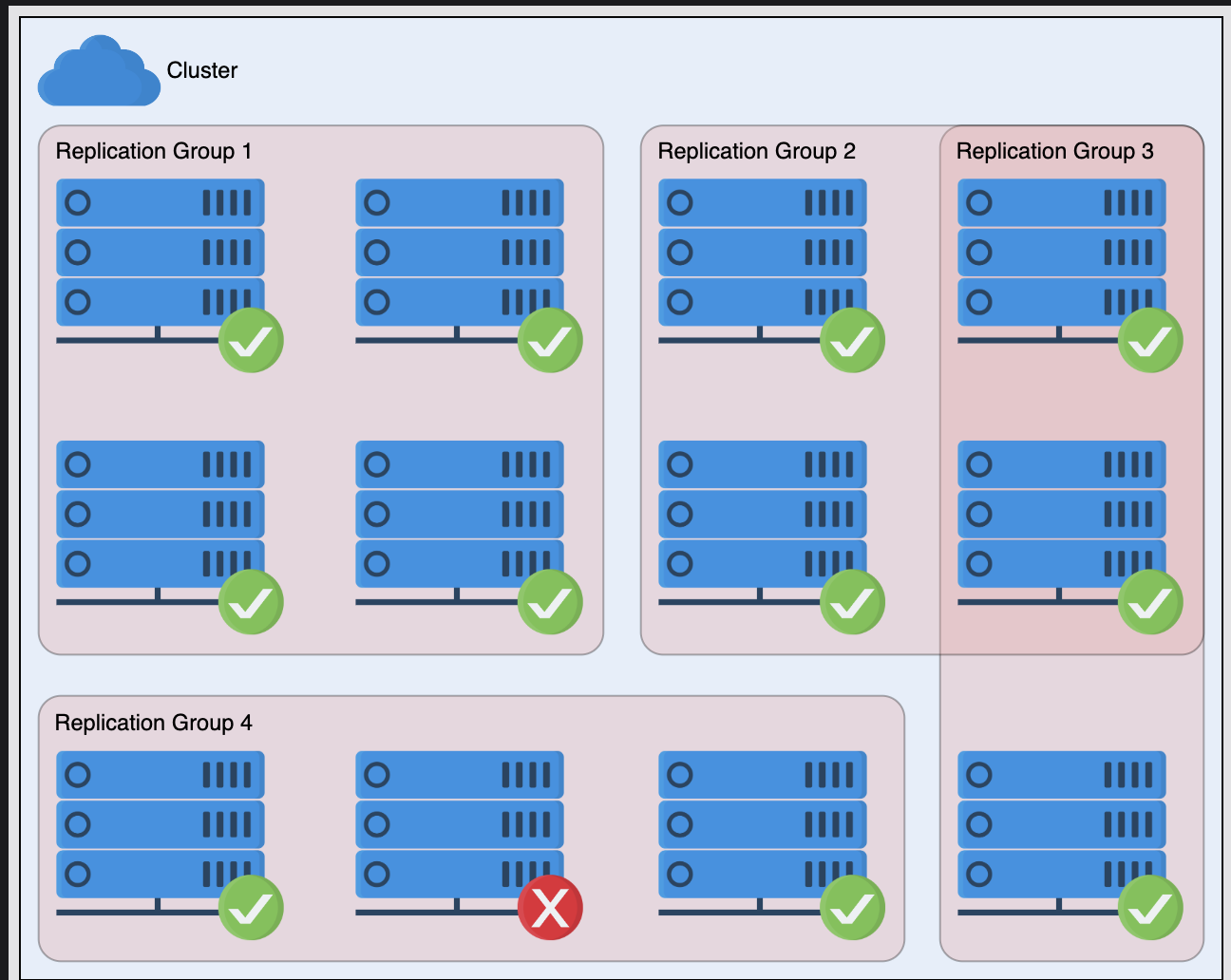
-
However, sometimes grey failures happen where one node cannot reach the leader. Before it triggers an election, it asks if a quorum of other nodes can reach the leader
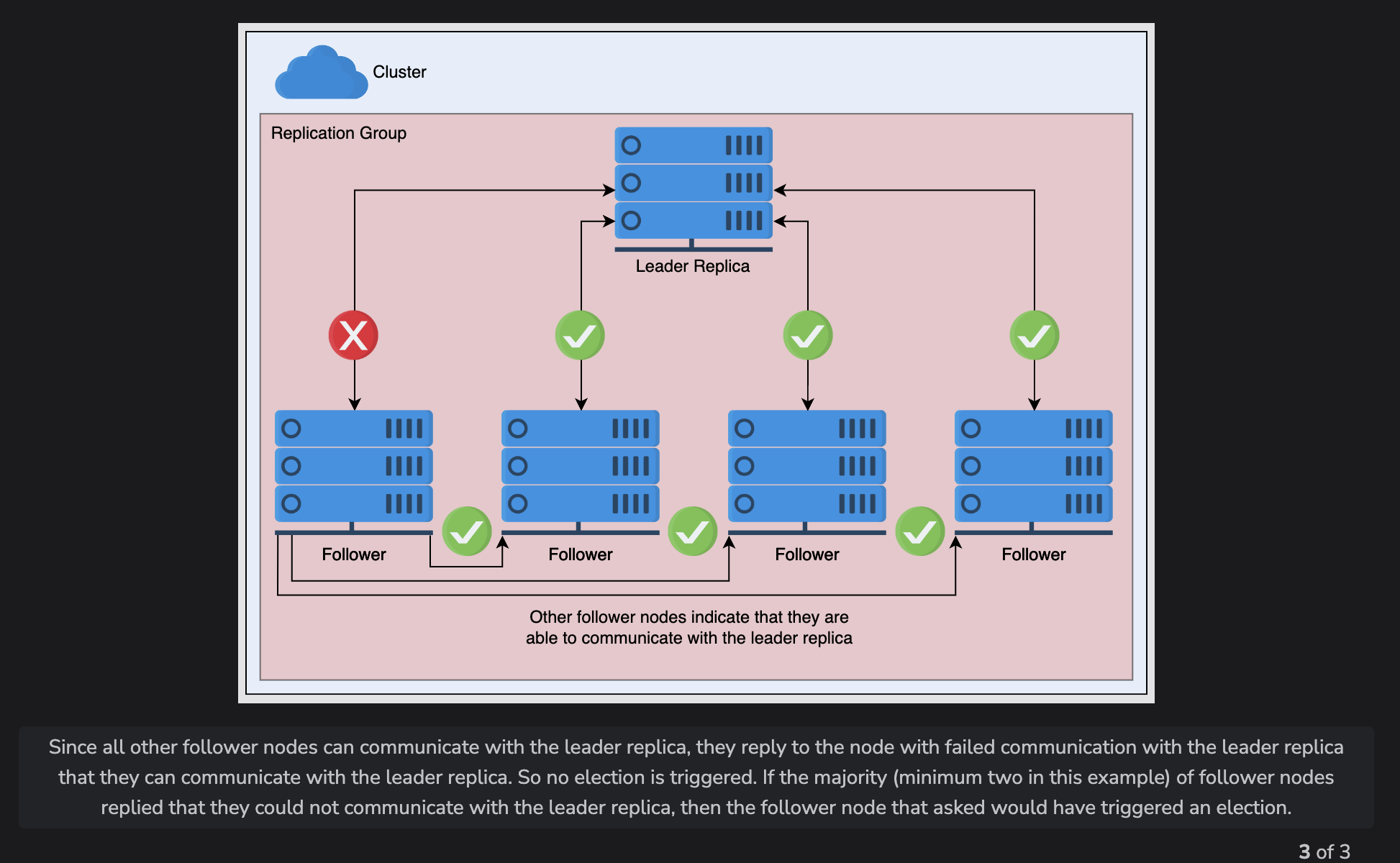
BigTable
- Key features
-
Single row transactions
-
No batching across row keys
-
Integer counters
-
MapReduce jobs as input source and output target
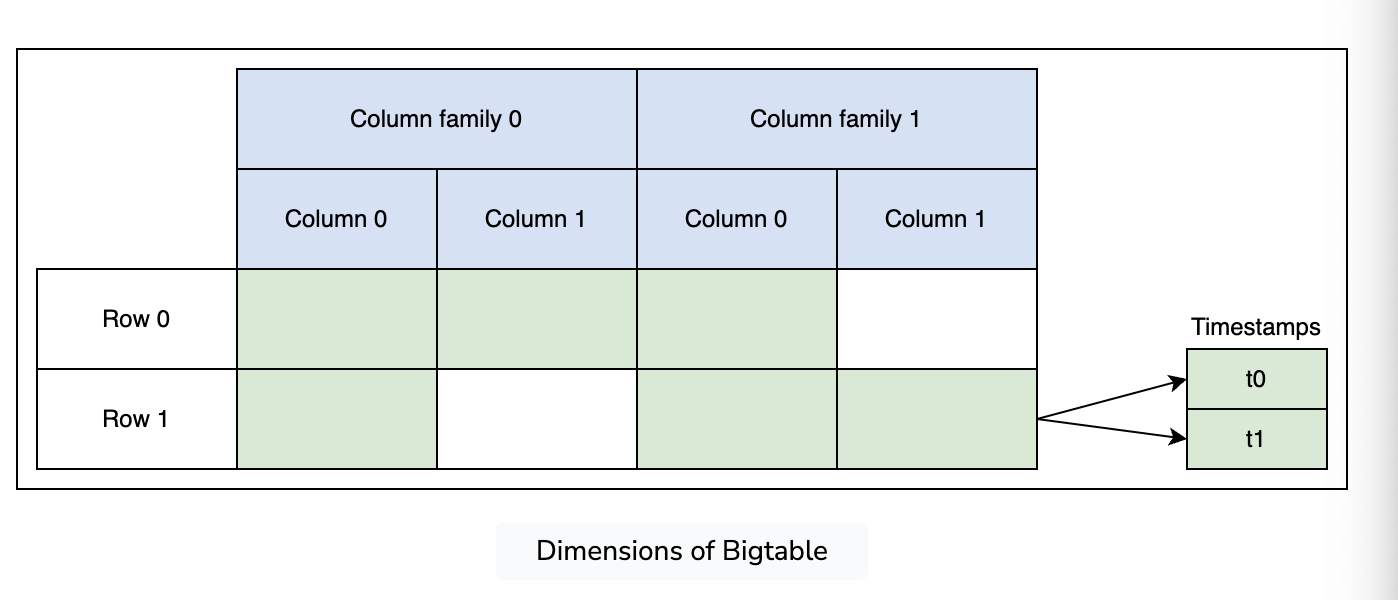
-
- Uses a column family style, with groups of columns and a timestamp within each cell
- Treats all data as raw byte strings
- All rows have a row key (64kb string), each write and read is atomic
- Column families allow for efficient read/write operations, since they usually hold data of the same type (data within a family is physically close)
- Also has timestamps, keeps the latest 3 versions
Components
Memtable
- Recent modifications in an in-memory, mutable sorted buffer
- When a memtable grows big enough, its gets flushed to disk as an SSTable
- Uses a write-ahead-log for this
SSTable (Sorted String Table)
- Components
- Data File
- Primary Index
- Bloom filter (for quickly checking if it’s in the data structure)
- Compression information
- Stats
- 64kb blocks
- Immutable k/v mappings used to represent tablet states, consisting of blocks, with block indexes facilitating efficient disk access, and can be loaded into memory for quick queries
Chubby
- Highly available and persistent distributed lock service
- typically runs with five operating replicas, similar to zoo
- Used in BigTable to ensure there’s only one operational manager
- Saves a bootstrap information as well as new tablet servers and failures
- ACLs too
Operations
- Locating tablets for a piece of data
- Uses a three level structure similar to a B+ tree
- root tablet’s location is stored in a Chubby file
- second tier contains all metadata tablets
- third tier contains all user tablets
- The root tablet is a pointer to other tablets
- first tablet in the metadata data is the root tablet, which is treated differently
- We cache tablet positions in the client library
- Client can then check the metadata server, which then goes to chubby, to get info
- Basically the thing to know is that this is similar to an inode, where there’s three layers of indirection
- A tablet is assigned to just one tablet server, the manager also maintains a record of unassigned tablets and allocates them to tablet servers that have enough space
- Manager requires heartbeats and locks via chubby to assure that a tablet server is holding a tablet
- New managers interact with each active tablet server after looking them up in the tablet server directory in chubby
Writes
- When a write is received by a tablet server, it gets checked to ensure to ensure data validity and proper formatting
- check authorizations in the lock
Reads
- Same thing as write, initial check is via authorization in chubby, and then loads the SS tables
Minor, Merging, and Major Compactions
- Minor compaction is when it flushes the memtable to disk and turns it into an sstable
- Merging compaction is when sstables become too many and we merge them together, although this could include deleted entries
- Major compaction is when we merge multiple sstables together and remove the deleted datace the tombstones are handled
Design Refinements
- Column family locality
- compression is also done on the column family locality to store data
- Tablet caches in two ways
- Scan cache - high level cache that stores k/v given to the tablet server
- Block cache - caches blocks, like page caching
- Bloom filters
- Bloom filters tell you 100% if it is not in the table.
- Quickly check which things are in a sstable
- Commit logs
- There’s only one big commit log
- Recovering servers must load off of another’s commit log
- Duplicate log reads are by sorting the entries by
<table, row name, log seq number>.
- Speeding up tablet recovery
- Most challenging and time consuming jobs is ensuring the tablet server gets all entries from the commit log
- Minor compactions are done before moving to reduce the amount of stuff needed to move.
System Design Wisdom
- Uses other services (Chubby and GFS) as building blocks
- Locality hints from the users for many of its optimizations, such as column families
- One log file per tablet is a way to allow individual tablets to recover
- Single manager interface
Megastore
- SQL based system
- Built on top of bigtable
- Main goal was to facilitate ACID transactions
Design
- Application server
- Used to deploy megastore, local replica on each application server, which writes to the local bigtable
- Megastore library
- Connects and implements paxos and replica picking
- Replication server
- Checks for unfinished writes, similar to a garbage collector, which provides paxos no-op commands
- Coordinator
- Keeps track of entity groups which its replicas has seen every Paxos write
- Bigtable
- Handles arbitrary reads and write throughputs
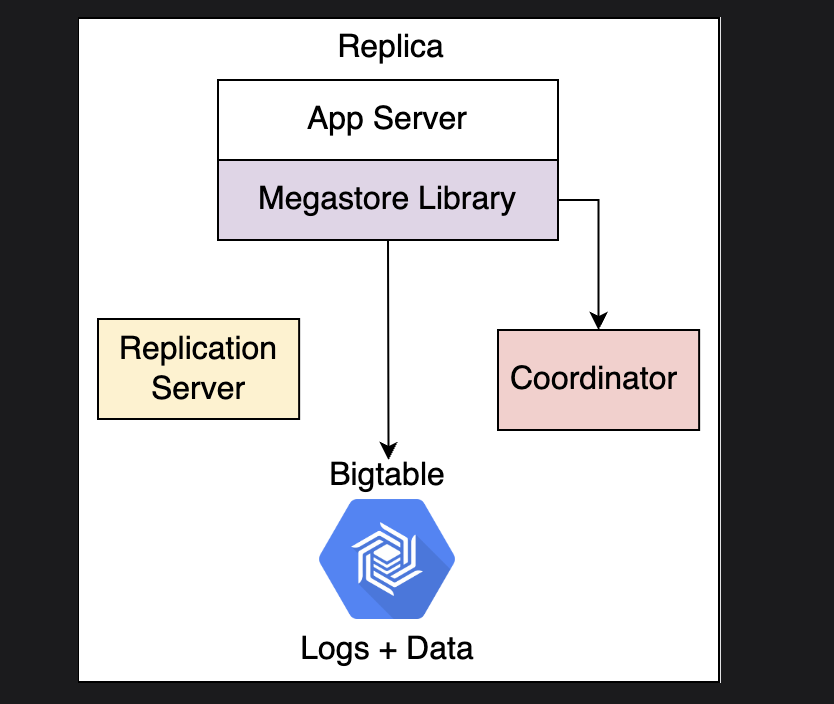
Replication Strats
- Async primary/secondary - write ahead logs are replciated to at least one secondary node, but log appends are recognized and serialized at the primary node while being sent down to the secondary nodes. Primary is responsible for ACID, but it is acceptable to have a node fail and a secondary take on a primary.
- Sync primary/secondary, primary node waits until its actually been replicated before doing a tx
- Optimistic replication, where no primary, and any node can accept the changes and propagate them async to other nodes. Better availability and latency, but transactions are not possible.
Paxos
- Megastore implements paxos, which has issues being slow
- But Paxos gives
- NO primary but a group
- WAL is replciated to all nodes
- Any node can start read/write
- Every log adds the changes only if a majority acks
- Remaining nodes eventually catch up
- Communication is hindered if a majority is down
- Entity groups are used to replicate
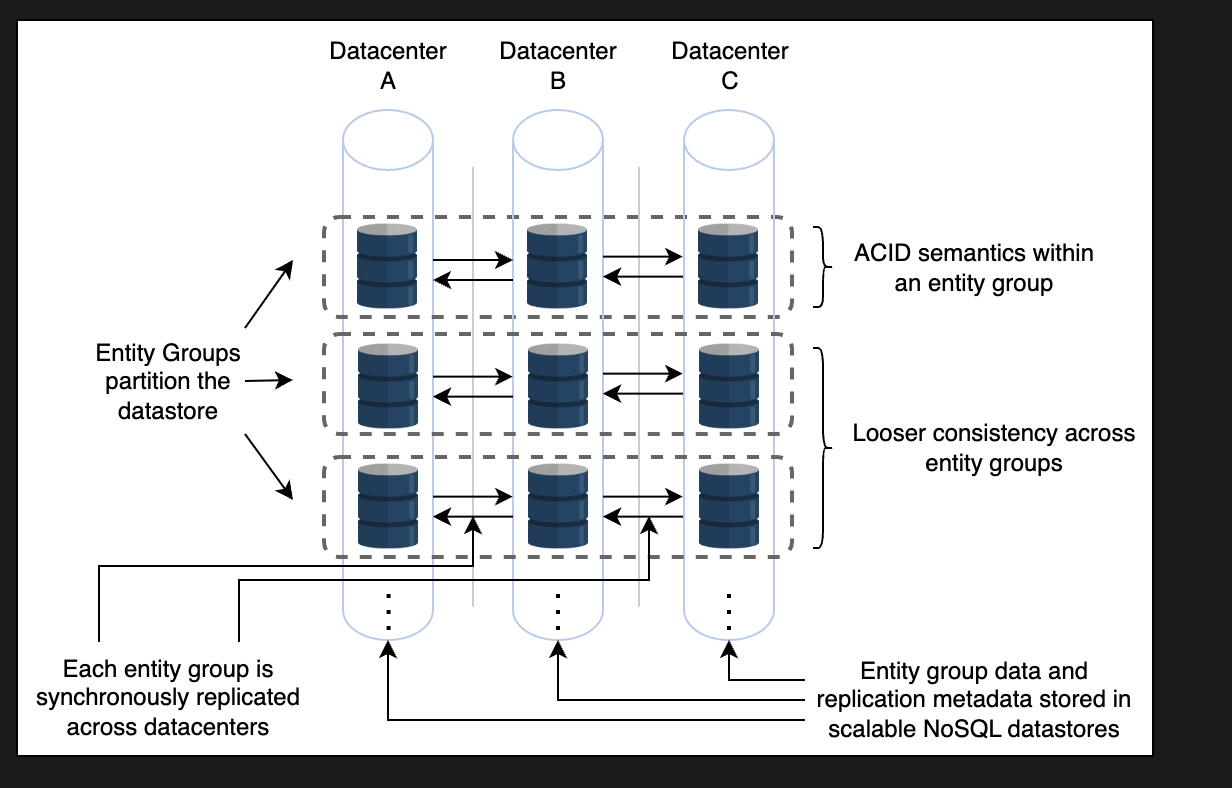
- In entity groups, entities are changed using single-phase ACID transactions, which paxos uses to replicate the common record
- 2pc can also be used
- Megastore async replicates between different entity groups. Local indexes have strong consistenty, but global ones have weak consistenty
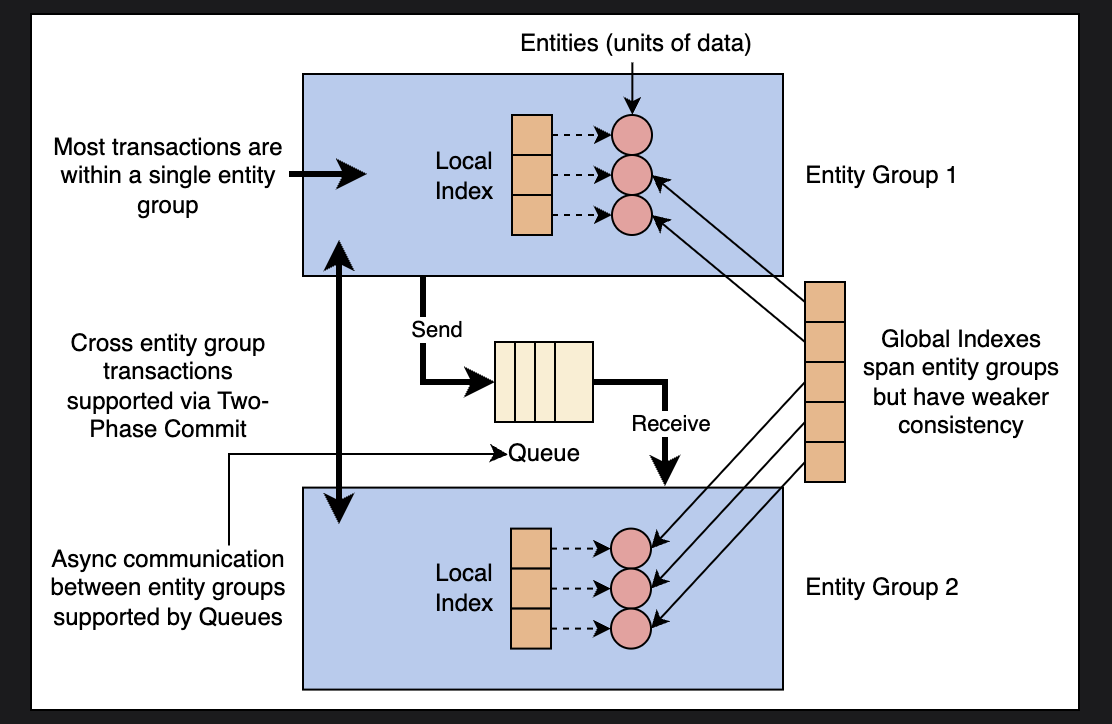
Megastore Data Model
- API design
- Relatively stable performance benefits
- Shift work from read time to write time since there’s definitely going to be more reads than writes
- Data model is strongly typed, similar to RDMS, where schemas and a collection of tables are named and typed.
- Key distinctions: root tables and child tables
- Child table needs to specificy a foreign key referring to a root table, and a root table and all its child tables make up an entity group
- Prejoining with keys
- normally, primary keys have surrogate values that idenitfy each row in a table
- Two layers of secondary indexes
- Local index: each group’s local index is used as a distinct index, which locates data inside an entity group
- Global index: encompasses many entity groups, used to locate entities without knowing which entity groups include them in advance
- All of this is splayed on top of big table to get atomicity, consistency, isolation, and durability
- Uses the versioning feature of bigtable to implement multi-version concurrency control
- Read consistency
- Gives you three levels
- Current: makes sure all committed writes have been executed, and does a read
- Snapshot: reads the latest committed write operation
- Inconsistent: reads the most recent value without considering the log’s state
- Gives you three levels
- Writes
- Writes do a current read before doing a write so it can find the latest offset for the log, then uses paxos to get all nodes to buy in, then commits it and updates it in bigtable
- Queues
- Transactional messaging among groups of entities are handled through queues, which is used for batching many changes into a single transaction
Replication in Megastore
- Paxos WAL is mostly where it sits
- Also allows local reads from anywhere, since paxos is used to make sure everyone is together
- Each log position is a paxos usage, which optimizes to skip the preparation phase and enter the acceptance phase when the same proposer makes continous proposals
- Leader decides which values are allowed ot use proposal 0
- Different types of replicas
- Witness replicas
- Have WALs and vote in Paxos
- Reduced storage costs because they don’t actually store the data
- Are able to avoid the need for an additional round trip when unable write
- Read only replicas
- Can’t vote
- Contain snapshots of the data
- Read only replicas can distribute the data over large geographic area, basically a CDN
- Witness replicas
Replicated Logs
- Replicated logs have many shapes, but we also allow holes in the logs for when consensus was not found
- Catching up
- Node checks if the entity group is up-to-date locally by contacting the coordinator of the local replica
- Then finds the position, which detemrines and picks a replica that has applied through the highest possibly commited log position
- Catches up by reading the values from the different replicas. Empty no-op values for ones that are disputed, Paxos then forces all the majority of the replicas to accept the no-op or previously comimtted write
- Coordinators oversee the entire process, and they themselves are locked in Chubby
Scaling Memcache
set,get,deleteoperations
Main data structures of memcache
-
Hash table
- Chained hash table, everything is a linked list
-
Cache item data structure
-
Slab allocator
- Memcached Items
- Item that holds data for a k,v pair
- allocators
- A slab is a list of memory sections containing objects (pages) categories by the memroize size range they fall into
- By default the memory is split into 42 slabs
- first slab for items less than 96 bytes
- second for 96-120 bytes
- etc
- Memcached Items
-
LRU list
- For evicting the oldest and least used items, LRU matches to different slabs
Memcache Design
- Adaptive slab allocator
- Peroidic rebalancing of slabs
- If slabs needs more memory if it is evicting a lot of items, or if an item that is evicted was being used 20% more recently than the average of the least recently used item in other slab classes
- When we identify a needy slab, we free up the least recently used slab and transer it to the needy class
- Short lived keys are pruned using a circular buffer than removes one item every second
Memcache Clustering
- Key load is managed by consistent hashing
- although this means we need a memcached router for balancing, hence https://github.com/facebook/mcrouter
- MC router talks with the memcache ASCII protocol
- Network efficiency issue: incast congestion
- When a large number of responses to request overload a DC’s cluster and rack switches, when we to rack to rack, such as broadcasting with memcache
- Use a sliding window, similar to TCP
- High load issues
- Stale sets
- When a sequence of concurrent operations get reordered
- Thundering herd
- When multiple clients attempt to request the same thing at once
- Solution: use leases
- We “lease” the key value to a client by allocating a token, to set the item, the client has to provide the token again
- A token can be invalidated if the Memcached server receives a delete request for the key
- Similar to load-linked and store-conditionals
- Stale sets
- Different applications need different sizes, what do we do?
- Different pools of memcached, such as low-churn keys and high-churn keys
- Replication within pools to improve latency and divide the load
- Sometimes we want to split the keyset, but other times we might just want to replicate the key set
- Small outages
- Add “gutter” servers, which do not rehash the key-value items to other Memcached using consistent hashing. K/V’s in the gutter pool are drained quickly
Regional Level Memcache
- Scaling a cluster natively makes it so that our networks start to face incast congestion
- We’d rather replicate clusters
- But how do we invalidate when we replicate?
- THere needs to be two ways of invalidation: either the backend DB invalidates the key on an update, or the client does
- We can set an invalidation daemon that discovers or just broadcasts UDP to all memcached instances to invalidate
- Note that the dameons batch as well
Controlling replication in regional pools
- How many places should keys be replicated?
- Create a regional pool of memcached servers that multiple clients share, and move data between different pools as needed
Bringing up new pools
- New pools should look at warm pools to replicate, not the DB, otherwise it threatens to overwhelm the DB
- To avoid races, we hold off
deleteoperations, and clients add to the new cluster instead of the old
Cross Regional Memcached
- Cross region replication is a huge pain
- 100-300 ms
- How do we deal with writes from a secondary region?
- User writes to one region, and reads from another
- Set a remote marker in the local region for a specific key
- Perform writes that are appended with the key and the remote marker
- Delete the key in the local cluster
- Eventual consistency considered acceptable in this case
Spanner
- https://www.cs.princeton.edu/courses/archive/fall16/cos418/docs/P6-Spanner.pdf
- Worldwide LTP, SQL semantics, horizontal scalability, availablity, transactional consistency
- Parts
- Client
- Load balancer
- Zone - between 100 and a few thousand servers
- Zone manager
- Placement driver, responsible for automated data transfer between zones
- Location proxy
- Uses the per zone location proxies to find spanservers for data
- Universe manager
- For interactive debugging
- Spanserver - consists of tablets
- Colossus - distributed file system that stores tablet’s state similar to B-tree format
Design
- Spanner is deployed as “universes”, and only a few are active at one time
- Each one relies on TrueTime to provide strong external consistency and global serialization
- Also performs automatic resharding based on data size and load
- Universe manager and placement driver are both singletons, although there are shadow replicas that will take over
- Each zone works like a cluster of bigtable servers, each spanserver has several tablets ranging from 100-1000
- (key:string, timestamp:int64) -> strings
- paxos and TrueTime are used to cover time, and Colossus is used to store data
- Each tablet stores metadata and logs for the state machines, and the paxos implementation supports time-based leaders with long-lived leaders (aka fastpaxos)
- Single leader fast paxos effectively function as raft
- Concurrency is handled via a lock table
- Each server enforces concurrency control based on the long-lived paxos leader
- Paxos leaders have around 10s for their leases
- Paxos group that has a participant leader that acts as the transaction manager, and the other replicas are participant followers.
- For transactions that span multiple groups, a coordinator is elected
- Note that we only lock for writes
- bully algorithm is used for leader election
Writes and Reads
- When a write is done, the lease vote is automatically extended, and leaders need to ask for a lease extension.
- Notably, it waits out the uncertainty before proceeding with a commit
- To serve reads, each replica in Spanner keeps track of the maximum timestap that it was up to date. When a read transaction comes in, it decides whether it’s able to serve it
- Commit protocol guaranteees that all nodes know the lower bound of a prepared transaction timestamp.
- We have to assign a timestamp for a snapshot reads, and snapshot reads are only done on replicas that are up to date
Database Buckets
- Spanner has an additional layer of abstraction over the bag of key-value mappings in the form of a directory or bucket
- All adjacent keys that begin with the same prefix
- All the data in the same bucket shares the same replication settings
- Move frequently accessed buckets into the same paxos group or place a bucket geographically closer to its accessors
- Spanner buckets differ from Bigtable ones because they don’t need to be lexicographically contiguous
- We can
movedirbuckets across Paxos groups, which then moves the data in the background. The metadata setting is then flipped in the background RCU style - We use a bucket to specify the geographical replication attributes and placements
- Two settings:
- Total number and type of replicas
- You can tune the amount of voting replicas and place them physically closer
- Read only - can’t vote, only allow for scaling reads
- Witness - Vote for the leader and commit write transactions, but don’t keep a copy of the data. Can’t serve as read leaders
- Read-write replicas - Does both, can be a leader
- Geographic placement of replicas
- Total number and type of replicas
- Two settings:
Data Model
- SQL-like, but Megastore had poor performance
truetime
- With truetime, any two transactions T1 and T2,m if T2 begins to commit after T1 completes committing, then T2’s timestamp is > T1’s timestamp
- Consistent timestamp allows easy snapshot isolation, since we can just read at a point in tiem
- Liskov, Barbara. “Practical Usesof Synchronized Clocks Undistributed Systems,” n.d.
CAP theorem and spanner
- does not guarentee uptime, but real databases need maint anyways, so it is “essentially CA”
- Since paxos is used, it opts for consistency over availability, as paxos is possible to livelock
DB Transactions
Read Transactions
- For read transactions, we buffer them on the client side until commits.
- Transactions writes are not visible to subsequent reads inside the same transaction
- Uses wound-wait to prevent deadlocks
- Read request
- The lead replica acquires a lock
- Read to update to date data from the replicas
- For read-only transactions
- within a single paxos groups: just send the read transaction to the group’s leader
- if it’s multiple paxos groups: then determine the \(s_{read}\) value on the last timestamp by doing consensus with leaders
- Or avoid the consensus round
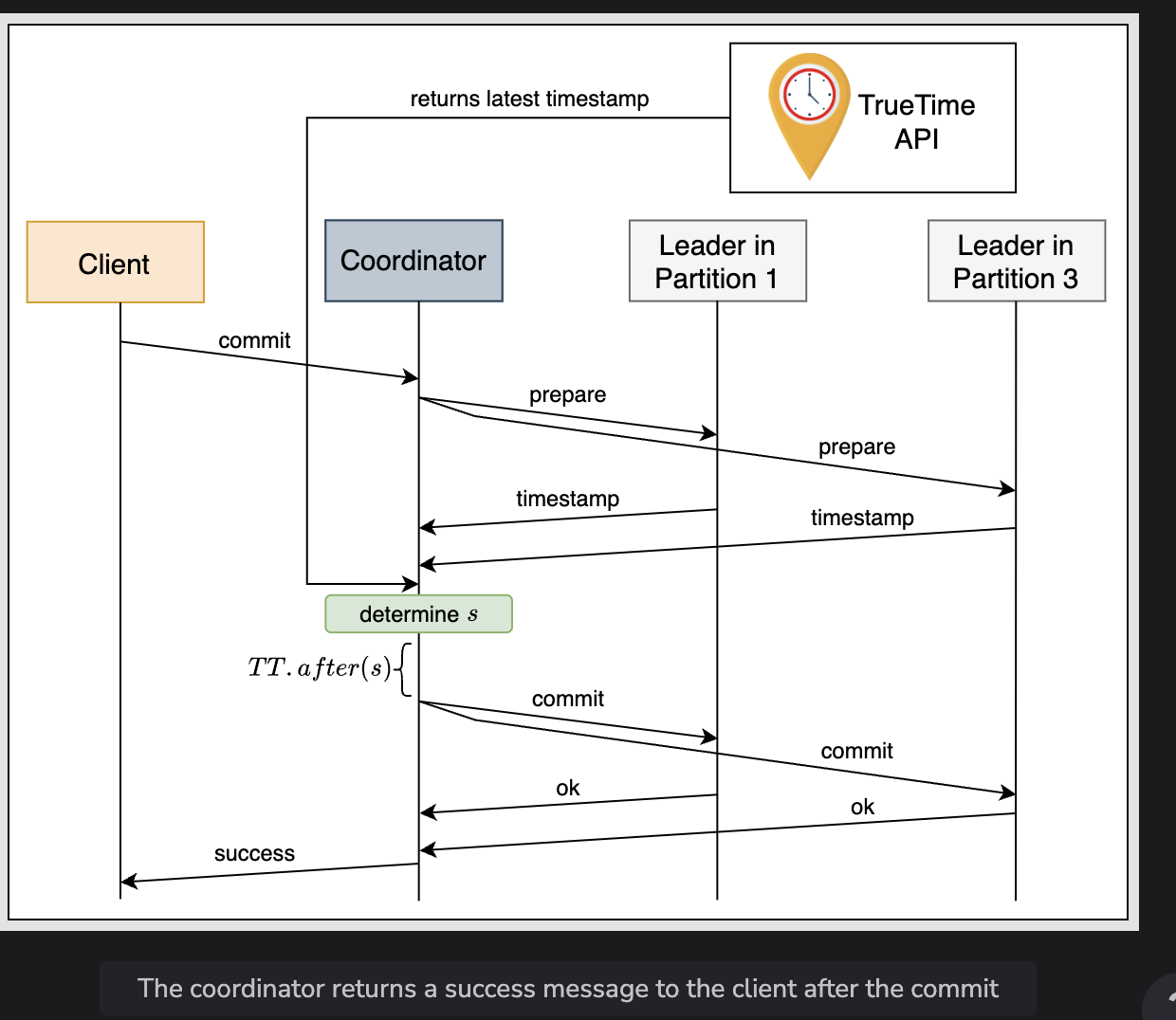
Uses a 2PC
- Guarentees isolation and strong consistency
- If participants in a 2PC are physically nearby, then it selects paxos groups closer
- Leader who aren’t coordinators gets access to write locks, and then also does prepare timestamps
- Coordinator roles
- The coordinator bypasses the prepare step and gets locks for writes, and recieves inputs from all the group’s leaders
- Commit transactions
- Greater than or equal all prepare timestamps to satisfy the invariants of read-write transactions
- Greater than TT.now().latest
- Greater than the timestamps of all the transactions that the leader coordinator has assigned previously
Schema Change Transactions
- Changing the schema in Spanner
- A future timestamp is determined in the prepare phase
- Consider that the t is the timestamp of a registered schema change transaction
Eval
- Important thing to understand about spanner is TrueTime, by putting bounds on clock drift, you acn get transactions
Spanner SWE Tea Series
- Spanner was ultimately based off of F1, which had implemented quite a bit of this before
- Shute, Jeff, Radek Vingralek, Bart Samwel, Ben Handy, Chad Whipkey, Eric Rollins, Mircea Oancea, et al. “F1: A Distributed SQL Database That Scales.” Proceedings of the VLDB Endowment 6, no. 11 (August 27, 2013): 1068–79. https://doi.org/10.14778/2536222.2536232.
- interesting secret sauce was about how they retry requests
- F1 previous had to fetch the entire protobuf value to do a partial decode
- Spanner wasn’t originally SQL, but they decided to do quite a bit of pushdown as a result
- Becoming a SQL system (Bacon, David F., Nathan Bales, Nico Bruno, Brian F. Cooper, Adam Dickinson, Andrew Fikes, Campbell Fraser, et al. “Spanner: Becoming a SQL System.” In Proceedings of the 2017 ACM International Conference on Management of Data, 331–43. Chicago Illinois USA: ACM, 2017. https://doi.org/10.1145/3035918.3056103.)
-
range extraction and pushdown
-
static decomposition of SQL down into
scan,filter, andapplyprimitives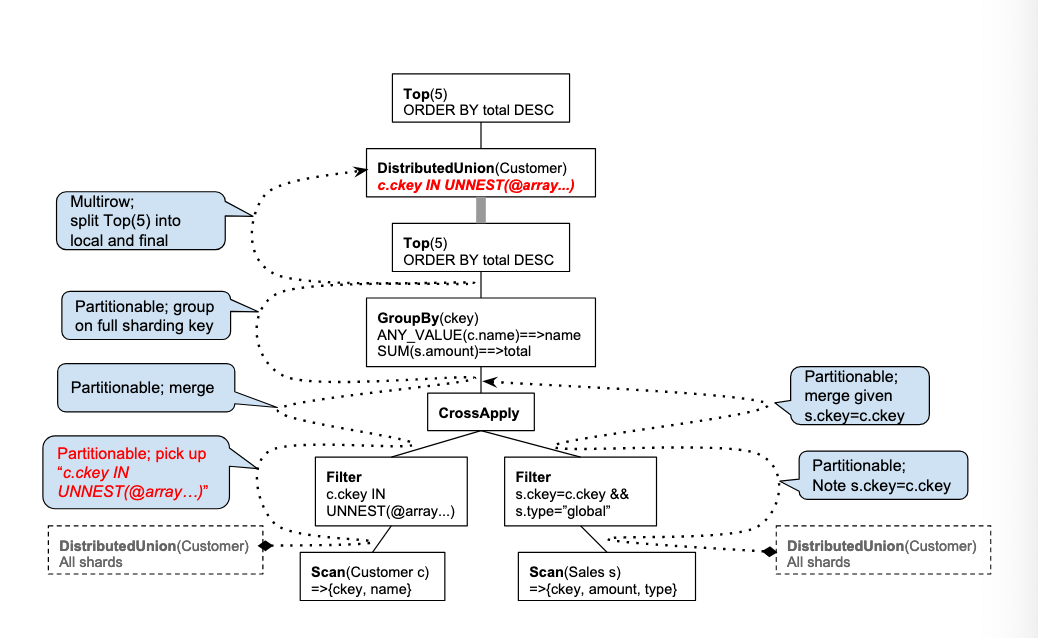
-
-
ressi
-
shard pruning
- location hints about the location of a particular shard
-
restart token
- not much mentioned but this seems to be the secret sauce here
-