the information plane within deep learning
drafts, Scaling laws for solution compressibility
[Transformers|Deep Neural Networks|AI] need to be explainable is a common enough refrain. I would say it’s a fairly uncontroversial statement that NLP is a field heavy on the experimental and light on the theoretical. With that in mind, I want to talk about the concept of “information plane”, a term coined by Schwartz-Ziv and Tishby (2017). For Schwartz-Ziv and Tishby, the information plane is “the plane of the Mutual Information values that each layer preserves on the input and output variables”. I think this can effectively been seen as a proxy for the learning curve or loss landscape, although “information plane” captures that trajectories within the information plane have two distinct phases Saxe et al (2019):
- an initial “fitting” phase where the mutal information grows
- a secondary “compression” phase where the mutal information decreases
To make this a little more concrete, I think you can see this as a learning curve analogy, where at first the neural network is attempting to memorize all the data until it runs out of space, and then a compression phase begins, where the softmaxes start to become hardmaxes. Now Saxe et al (2019) state that while it’s been hypothesized that this compression phase is responsible for generalization properties, they also point out that not all neural networks exhibit compression dynamics. Double saturating networks, such as those that use tanh or sigmoid, do exhibit compression, whereas ReLUs do not. In addition, randomess during the training process does not seem to affect compression, which brings us to a potentially murky territory: could a network learn without compression?
Saxe et al have this diagram in their paper:
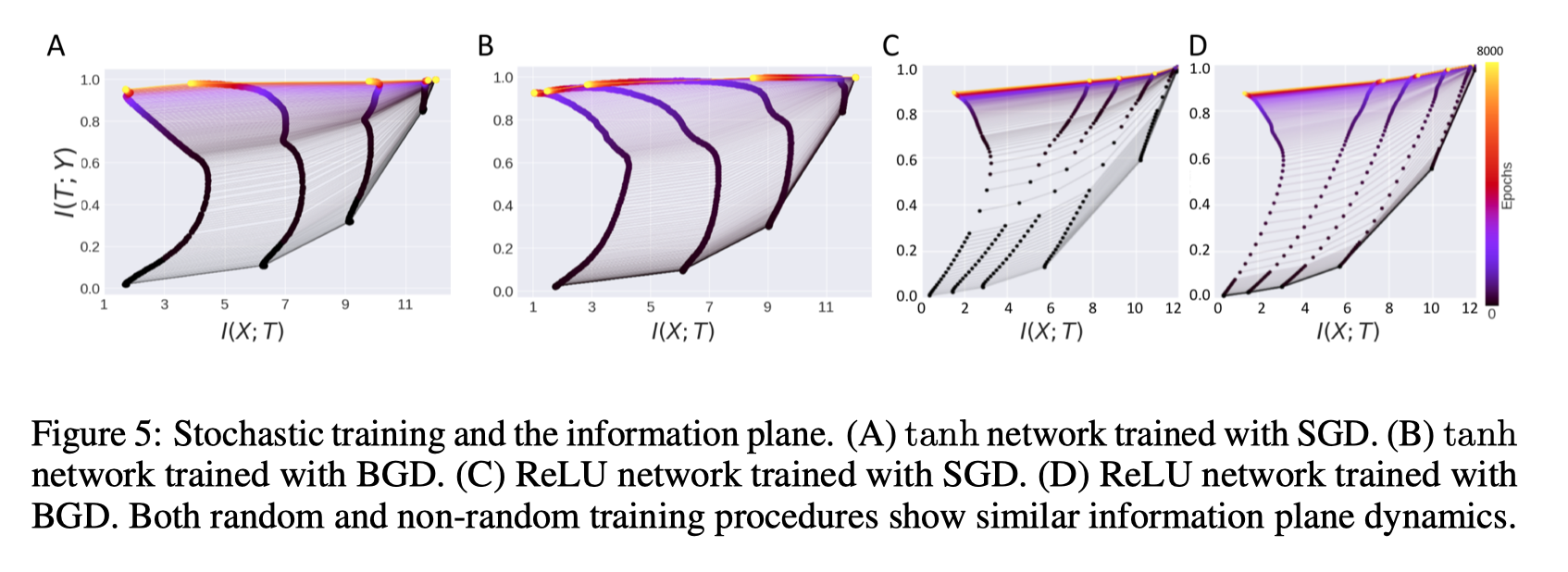
What’s interesting here is that you can see tanh networks make a beeline for compression towards later epochs, but the ReLUs do not, which means that information must be preserved somehow within the ReLUs. The question then becomes: was the information complexity of the input dataset not high enough to exhibit compression, or do ReLUs simply never exhibit compression and therefore are unable to learn certain types of input?
If we step back to the statistical idea of minimum sufficiency (a statistic is minimially sufficient where you can maintain the accuracy of predictions, basically a lossless compression of prediction power), we can make some inferences towards what’s called the “information bottleneck” in Tishby et al (1999). What Tishby et al (1999) tells us is that there is a minimum bound on how much information you can compress before you begin to lose prediction accuracy. Looking at it from that perspective, the information plane is actually just where a neural network searches for the information bottleneck!