Pavlick and Kwiatkowski: Inherent Disagreements in Human Textual Inferences
-
Pavlick, Ellie, and Tom Kwiatkowski. “Inherent Disagreements in Human Textual Inferences.” Transactions of the Association for Computational Linguistics 7 (November 2019): 677–94. https://doi.org/10.1162/tacl_a_00293.
Summary
- Talks about how human annotations and disagreements from those are not derived from statistical noise
- More context does not necessarily mean more agreement, once the input reaches sentence/passage, disagreements hold relatively steady
- We assume what people write is what they mean, but actually there’s a pretty big gap between what people mean <-> what they write <-> what they interpret <-> what they infer. NLP models currently only model the 2nd and 3rd arrows.
- punted on precise definitions of “real world” and rather tried to have their models approximate “what humans do”
Annotations
- Uses a combination of RTE2, SNLI, MNLI, JOCI, and DNC
- RTE2 - premises/hypothesis combos
- SNLI - premises from image captions, hypoteshis from existing NLI dataets paired with hypotehsis that were automatically generated
- MNLI - Same as SNLI but with a range of text genres
- JOCI - “commen sense” inferences
- DNC - mostly naturally occuring premises paired with template generated hypothesis

Preprocessing
- They had 500 workers complete and rank the response on a slider

- Continous scale not always the best, they had to do some z-score normalization in order for all the data to make sense
Analysis
-
Ultimately wanted to judge how much “noise” exists in the annotation process
-
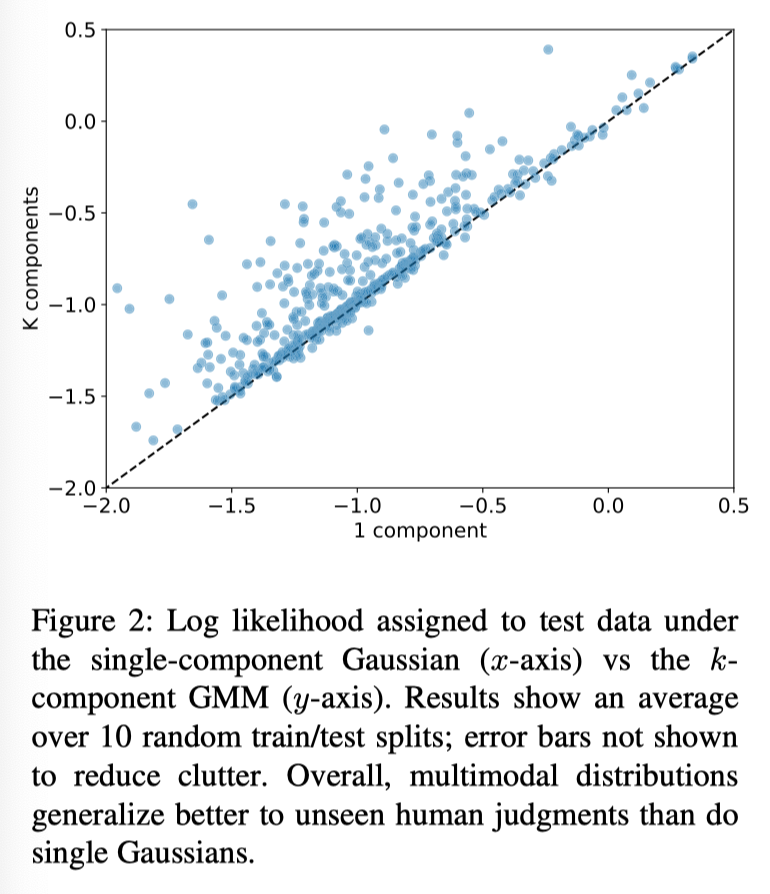
If there is a single truth, then the the “noise” should be generalizable with a single gaussian distribution
-
If there are “multiple” truths, then a gaussian mixture model should be correct
-
Assumption: if a single truth exists, the GMM woul be the exact same as the gaussian
-
Model chooses to fit towards the GMM than the gaussian
-
Example: is the word “swat” forceful? Is “confess that” factive?
-
In the first section, they note that the annotations can be modeled by the GMM, implying that humans believe there are multiple “truths”
- NLP models currently only believe there is one truth to model
Context
- Sampled sentences from wikipedia, and considered each sentence to be a premise, and generated a hyptothesis by replacing the corresponding a word from the premise with a substiute word, where the substitue word is either a hypernym/hyponym, antonym, or co-hyponym
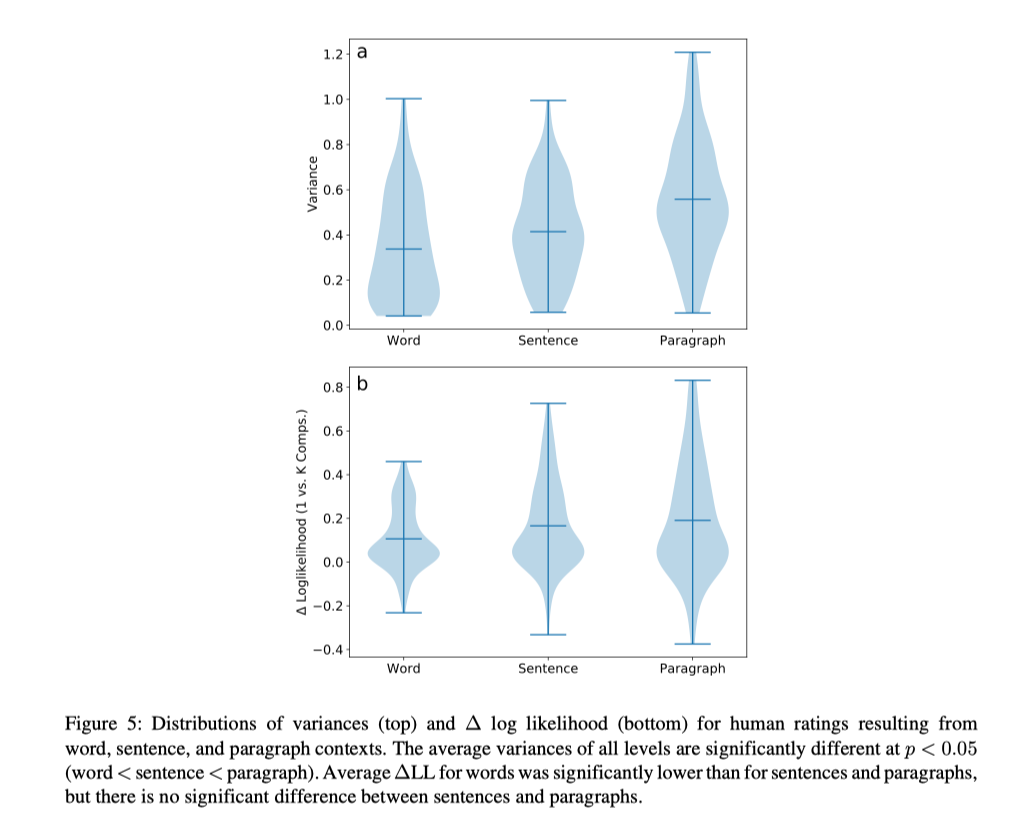
- Collected ratings at 3 levels
- word
- sentence
- passage
- Disagreements among raters actually increase when more context is shown
- Definitely some confounds abound
Model Predictions
- Is this a problem at all?
- what if the underlying distributions already reflect the distributions observed in human judgements, and the models already adaquetely capture that with softmax?
- since nli is usually treated as a classification, they discretize (after experimenting with z-normalied human scores) by mapping into different bins
entailment~/~contradiction~/~neutrallabel bins
- They used a pretrained bert and fine tuned it on the labels
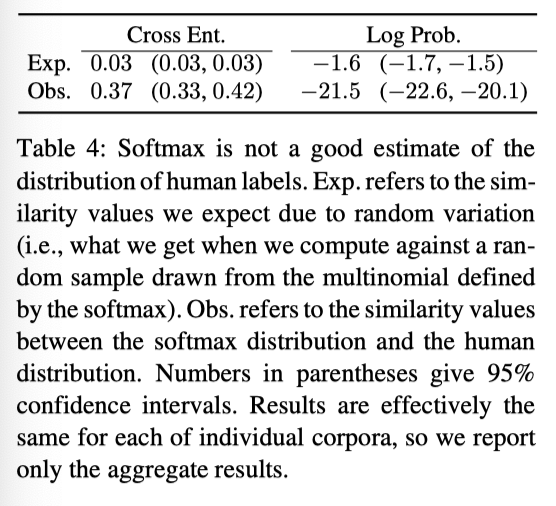
- Attempted to see how well bert captured the underlying multi-modal distribution with a softmax
-
found that the softmax is a poor approximation
-