natural language inference lecture
Tags: ling-ga 1012 (nlp and semantics)
intro
-
Motivating question:
can neural network methods do anything that resembles compositional semantics?- What’s our metric? How do we know we’ve accomplished a goal?
-
also sometimes called recongizing textual entailment (rte) - same as nli
-
example:
premise->hypothesis, does the premise entail the hypothesis?-
Ido Dagan 05
We say that T entails H, if typically, a human reading T would infer that H is most likely true
-
NLI entailment is a lot more loose than semantic entailment
- same looseness applies to contradiction
-
-
what is the meaning of a sentence?
- this is unproductive, we can’t really know what “““meaning””” is
- alternative question: what concrete phenomena do you have to deal with to understand a sentence?
-
focus on behaviors instead
-
for NLI to work, you need to understand a lot:

-
NLI is an ungrounded tasks - we do not require systems to look at situations outside of langauge
-
-
if you know the truth condition of two sentences, can you work out if one entails the other?

-
NLI asks us to reasonable about things even if we don’t know what it means
datasets
- datasets: FraCas Test Suite, Recongizing Textual Entailment (RTE), Sentences Involving Compositional Knowledge (SICK-E), Stanford NLI Corpus (SNLI), Multi-Genre NLI (MNLI), Crosslingual NLI (XNLI), SciTail
- what about multiple events?
- two sentences about a boat in different places, we assume same boat, say contradictoin
- two sentences unrelated, label neutral
- but then the boat question must be talking about neutral
- but then contradiction only occurs when sentences are extremely general and broad
- thus we must impose a rule that sentences are almost always taken to mean the same event
- this means that contradiction == “any situation where two sentences can’t be describing the same event”
-
often times this can be referred to with photos (i.e. can two sentences be describing the same photo?)
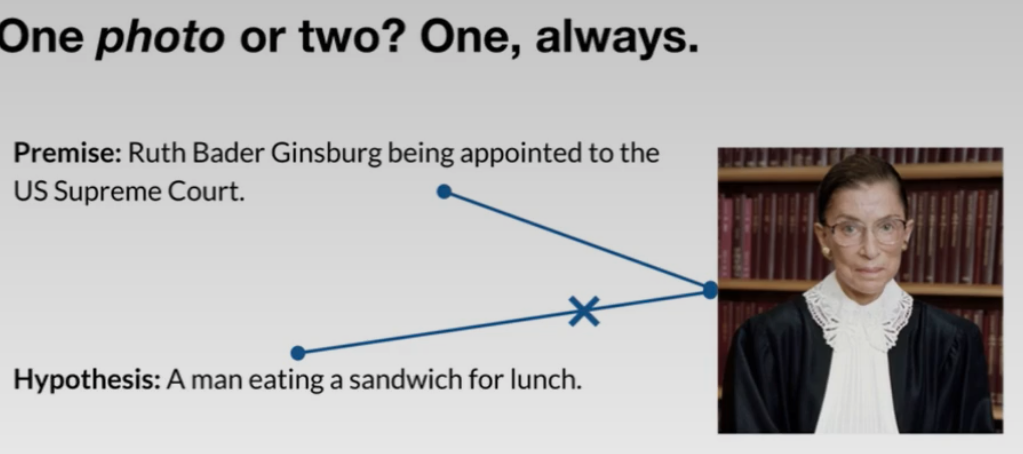
- Stanford NLI Corpus (SNLI) uses this
- Multi-Genre NLI (MNLI) goes for this, but goes beyond visual scenes
-
- annotation artifacts
-
somewhat possible to infer the premise from the hypothesis by the way it’s worded
-
models can do moderately well on NLI without looking at the premise
-
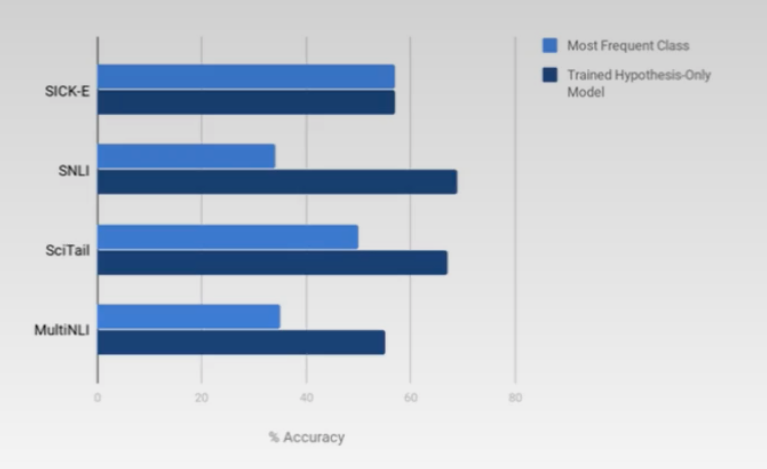
learning
Feature based models
- logistic regression, bag of words features on hypthesis, bag of word-pairs features to capture alignment, tree kernels
natural logic
- rules based
- non ML work on NLI is here
- formal logic for deriving entailments between a pair of sentences
- operates directly on words
- generally sound, entailment here means actual entailment
- but not complete, cannot detect some entailments
- requires clear structural parallels
- most NLI datasets won’t work with this
theorem proving
- attempts to translate sentences into logical forms
- open-domain semantic parsing is still hard
- more difficult than natural logic
deep learning
- 2015-17 - attempted to built DL systems that understood natural logic
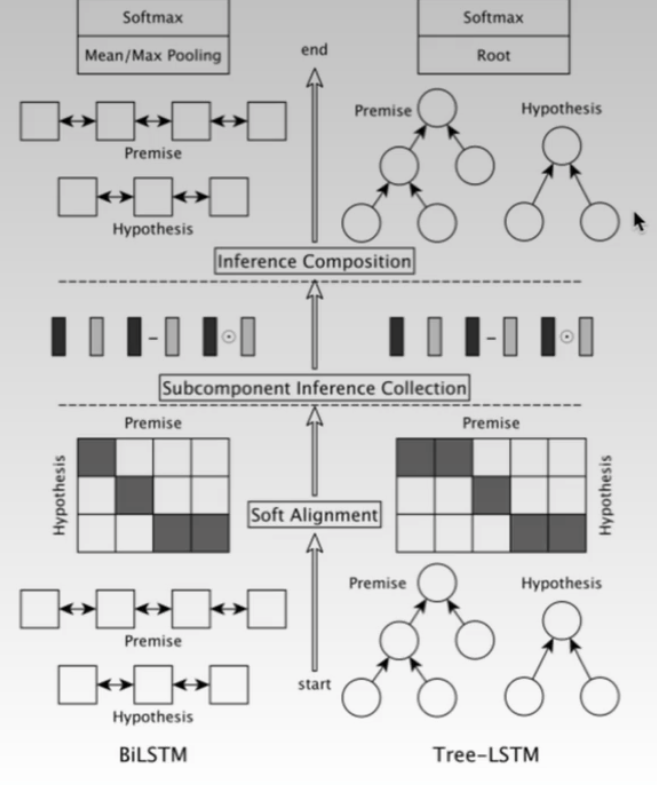
- machinery has gotten very complex, and BERT style models have replaced it
- transformers have replaced it
applications
- 3 major types
-
direct application
- original motivation
- multi-hop reading comprehension like OpenBook and MultiRC use it
- integrating Stanford NLI Corpus (SNLI)/Multi-Genre NLI (MNLI) trained ESIM model into a larger model in two places helps to select and combine relevant evidence for a question
- long form text generation can use NLI to prevent hte model from saying things that contradicts itself
- not as useful as a direct application
-
nli as a research and evaluation tasks
- very used for benchmarking
- glue
- caveat
- state of the art benchmark is very close to human performance
- in other words, state of the art datasets are not high quality enough, so the datasets are “solved”
-
nli as a pretraining task in transfer learning
- if you teach a model NLI, it should be reasonably good at other tasks
- take a model, fine tune it on MNLI, and then fine tune it again
- this works well even in conjunction with strong baselines for pretraining like RoBERTa
-